问题导读 1.hbase安装在什么情况下会发生,启动之后自动宕机 2.hbase安装目录该如何选择? 3.hbase目录如果出现权限不一致,会发生什么情况? 4.如果只有一个节点有临时目录会出现什么情况? Hbase集群安装前注意 1) Java:(hadoop已经安装了), 2) Hadoop 0.20.x / Hadoop-2.x 已经正确安装( hadoop安装参考hadoop2完全分布式最新高可靠安装文档 ),并且可以启动 HDFS 系统,并且需要确保hdfs能够上传和读写文件。 例如:3) ssh 必须安装ssh , sshd 也必须运行,这样Hadoop的脚本才可以远程操控其他的Hadoop和Hbase进程。ssh之间必须都打通,不用密码都可以登录。ssh打通可以参考:CentOS6.4之图解SSH无验证双向登陆配置 、linux(ubuntu)无密码相互登录高可靠文档 4) NTP:集群的时钟要保证基本的一致。 稍有不一致是可以容忍的,但是很大的不一致会 造成奇怪的行为。 运行 NTP 或者其他什么东西来同步你的时间.ubuntu ntp时间同步服务器搭建与使用 5) ulimit 和 nproc: FAQ: Why do I see "java.io.IOException...(Too many open files)" in my logs? 异常。还可能会发生这样的异常 2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient: ExceptionincreateBlockOutputStream java.io.EOFException 6)在Ubuntu上设置ulimit 复制代码 hadoop 运行Hbase和Hadoop的用户 。如果你用两个用户,你就需要配两个。还有配nproc hard 和 softlimits. 在文件 /etc/security/limits.conf 添加一行下面内容:hadoop soft/hard nproc 32000 复制代码 session required pam_limits.so 复制代码 -------------------------------------------------------------------------------------------------------------- 一、在 /etc/pam.d/common-session 加上这一行: session required pam_limit.so 复制代码 二、在文件 /etc/security/limits.conf 添加如下两行一行, hadoop - nofile 32768
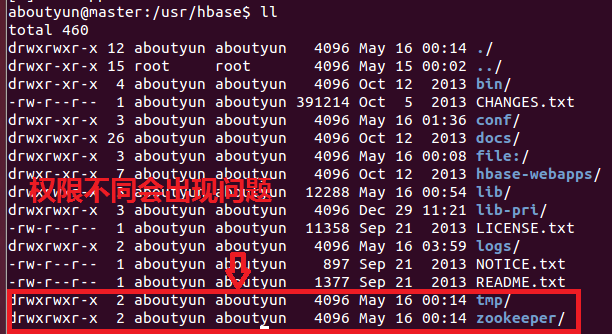
hadoop hard nproc 16384 复制代码 hadoop - nofile 32768 hadoop hard nproc 16384 这个的含义是什么?-------------------------------------------------------------------------------------------------------------- 分布式模式配置 注意的问题: 就是用户权限, 很多人在安装的时候随便选择了一个目录,结果不能访问,所以你的hbase起来之后,过会就挂掉了。一、新建文件,并注意权限问题 hbase临时目录 <property>
<name>hbase.tmp.dir</name>
<value>file:/usr/hbase/tmp</value>
</property> 复制代码 zookeeper目录: <property>
<name>hbase.zookeeper.property.dataDir</name>
<value>file:/usr/hbase/zookeeper</value>
</property> 复制代码 二、每个节点都必须创建文件夹,否则也会出现regionserver自动挂机。 1.1首先下载hbase http://pan.baidu.com/s/1sjubg0t 密码: crxs1.2上传压缩包到Linux 新手指导:使用 WinSCP(下载) 上文件到 Linux图文教程 。1.3解压 复制代码
1.4配置conf/hbase-env.sh
export JAVA_HOME=/usr/jdk1.7
# Tell HBase whether it should manage it'sown instance of Zookeeper or not. 复制代码 一个分布式运行的Hbase依赖一个zookeeper集群。所有的节点和客户端都必须能够访问zookeeper 。默认的情况下Hbase会管理一个zookeep集群。这个集群会随着Hbase的启动而启动。当然,你也可以自己管理一个zookeeper集群,但需要配置Hbase。你需要修改conf/hbase-env.sh里面的HBASE_MANAGES_ZK 来切换。这个值默认是true的,作用是让Hbase启动的时候同时也启动zookeeper.# Tell HBase whether it should manage it's own instanceof Zookeeper or not.
exportHBASE_MANAGES_ZK=true 复制代码 <configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:8020/hbase</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>file:/usr/hbase/tmp</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://master:60000</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>file:/usr/hbase/zookeeper</value>
</property> 复制代码 8020 /hbase.注释:hadoop1.X中使用的hdfs://master:9000 /8020 /这个端口是由core-site.xml来决定 <property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
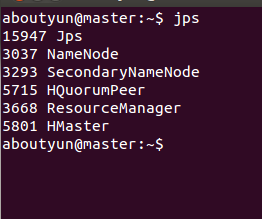
</property> 复制代码 hbase.rootdir :这个目录是region server的共享目录,用来持久化Hbase。URL需要是'完全正确'的,还要包含文件系统的scheme。例如,要表示hdfs中的'/hbase'目录,namenode 运行在node1的49002端口。则需要设置为hdfs://master:49002/hbase。默认情况下Hbase是写到/tmp的。不改这个配置,数据会在重启的时候丢失。默认: file:///tmp/hbase-${user.name}/hbasehbase.cluster.distributed :Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面。hbase.zookeeper.property.clientPort :ZooKeeper的zoo.conf中的配置。 客户端连接的端口。hbase.zookeeper.property.dataDir :ZooKeeper的zoo.conf中的配置。 快照的存储位置1.6配置conf/regionservers 1.7替换hadoop的jar包 注意的问题: hbase使用遇到 Class path contains multiple SLF4J bindings.错误解决方案 /usr/hbase/lib rm slf4j-log4j12-1.6.4.jar 1.8分发hbase 复制代码 2. 运行和确认安装 2.1当Hbase托管ZooKeeper的时候 2.2独立的zookeeper启动(如果另外安装,可以选此) 3. 测试 可以使用jps查看进程:在master上:
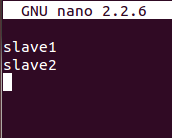
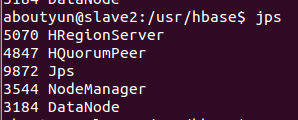
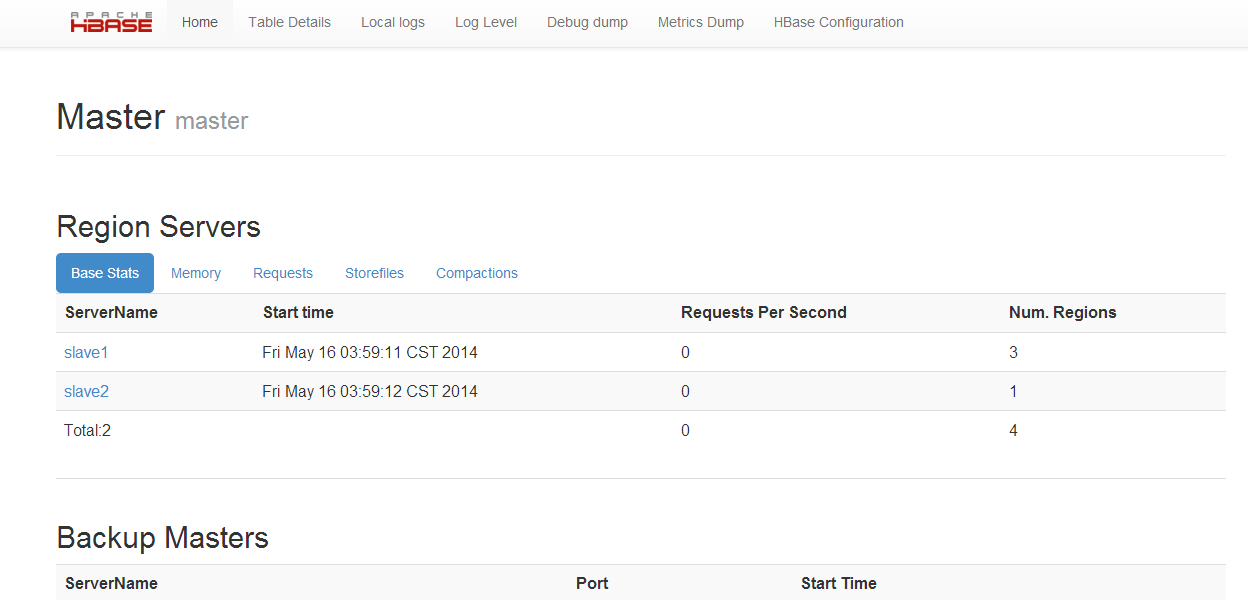
在slave1,slave2(slave节点)上
4. 安装中出现的问题 1 )用./start-hbase.sh启动HBase后,执行hbase shell # bin/hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Version: 0.20.6, rUnknown, Thu Oct 28 19:02:04 CST 2010 复制代码 hbase(main):001:0> create 'test',''c 复制代码 NativeException: org.apache.hadoop.hbase.MasterNotRunningException: null FATAL org.apache.hadoop.hbase.master.HMaster: Unhandled exception. Starting shutdown. java.io.IOException: Call to node1/10.64.56.76:49002 failed on local exception: java.io.EOFException 解决: FATAL org.apache.hadoop.hbase.master.HMaster: Unhandled exception. Starting shutdown. java.lang.NoClassDefFoundError: org/apache/commons/configuration/Configuration 解决: ERROR: java.io.IOException: Table Namespace Manager not ready yet, try again later at org.apache.hadoop.hbase.master.HMaster.getNamespaceDescriptor(HMaster.java:3101) at org.apache.hadoop.hbase.master.HMaster.createTable(HMaster.java:1738) at org.apache.hadoop.hbase.master.HMaster.createTable(HMaster.java:1777) at org.apache.hadoop.hbase.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java:38221) at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2146) at org.apache.hadoop.hbase.ipc.RpcServer$Handler.run(RpcServer.java:1851) 解决: 2 注意事项: <value>hdfs://node:49002/hbase</value> <value>hdfs://node:49002/hbase</value> hbase0.96与hive0.12整合高可靠文档及问题总结 

 /2
/2 











 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡




