楼主我想请问,我成功运行了本地模式验证,但是伪分布式运行命令start-dfs.sh时,出现command not found的错误。 并且再次尝试本地模式验证时,出现如下错误:
Java HotSpot(TM) Client VM warning: You have loaded library /usr/local/hadoop/hadoop-2.7.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
15/08/11 21:28:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/08/11 21:28:17 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
15/08/11 21:28:17 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
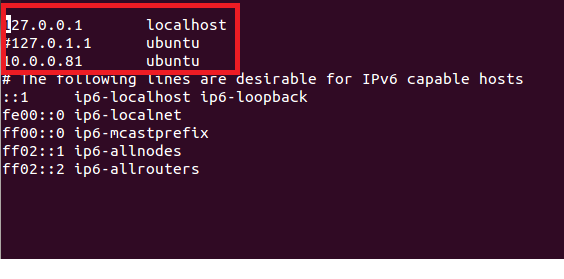
java.net.ConnectException: Call From lab401-virtual-machine/10.0.0.81 to localhost:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused…………

 /2
/2 


















 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡






