CentOS 6.6 搭了hadoop环境,win7下IDE装了hadoop插件,mr跑不起来。
[mw_shl_code=bash,true]package com.linewell.tomcat.logs;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/**
* 建立Mapper类TokenizerMapper继承自泛型类Mapper
* Mapper类:实现了Map功能基类
* Mapper接口:
* WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类应该实现此接口。
* Reporter 则可用于报告整个应用的运行进度,本例中未使用。
*
*/
public static class TokenizerMapper extends Mapper<Object,Text,Text,IntWritable> {
/**
* IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口,
* 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为int,String 的替代品。
* 声明one常量和word用于存放单词的变量
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
* Mapper中的map方法:
* void map(K1 key, V1 value, Context context)
* 映射一个单个的输入k/v对到一个中间的k/v对
* 输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
* Context:收集Mapper输出的<k,v>对。
* Context的write(k, v)方法:增加一个(k,v)对到context
* 程序员主要编写Map和Reduce函数.这个Map函数使用StringTokenizer函数对字符串进行分隔,通过write方法把单词存入word中
* write方法存入(单词,1)这样的二元组到context中
*/
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
/**
* Reducer类中的reduce方法:
* void reduce(Text key, Iterable<IntWritable> values, Context context)
* 中k/v来自于map函数中的context,可能经过了进一步处理(combiner),同样通过context输出
*/
public void reduce(Text key,Iterable<IntWritable> values,Context context)
throws IOException,InterruptedException {
int sum = 0;
for(IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception{
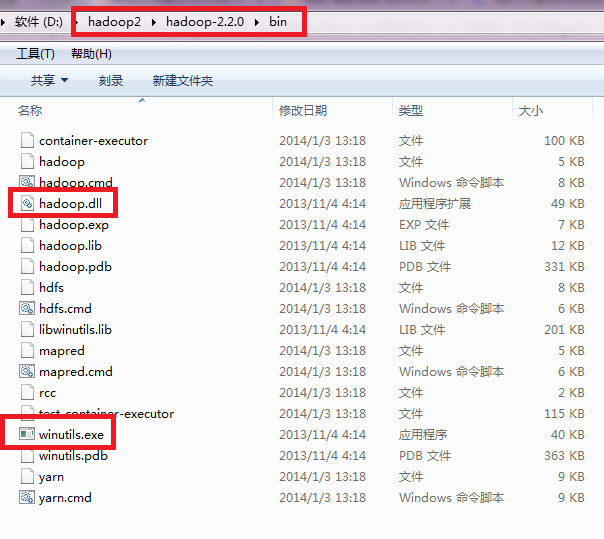
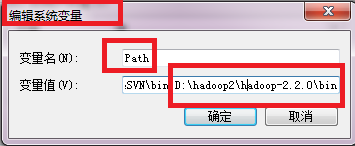
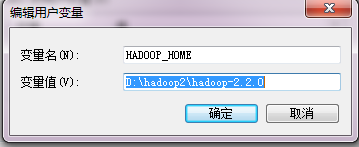
System.setProperty("hadoop.home.dir", "f:/master/hadoop");
/**
* Configuration:map/reduce的j配置类,向hadoop框架描述map-reduce执行的工作
*/
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://master:9000");
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", "master:8032");
String[] ioArgs={"hdfs://master:9000/log","hdfs://master:9000/log_out"};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if(otherArgs.length != 2) {
System.err.println("Usage:wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf,"word count"); //设置一个用户定义的job名称
job.setJarByClass(WordCount.class);
//设置Map、Combine和Reduce处理类
job.setMapperClass(TokenizerMapper.class); //为job设置Mapper类
job.setCombinerClass(IntSumReducer.class); //为job设置Combiner类
job.setReducerClass(IntSumReducer.class); //为job设置Reducer类
//设置输出类型
job.setOutputKeyClass(Text.class); //为job的输出数据设置Key类
job.setOutputValueClass(IntWritable.class); //为job输出设置value类
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //为job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //为job设置输出路径
System.exit(job.waitForCompletion(true)? 0 : 1); //运行job
}
}[/mw_shl_code]
2015-07-15 15:44:22,755 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1173)) - fs.default.name is deprecated. Instead, use fs.defaultFS
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/I:/%e5%ae%89%e8%a3%85%e9%83%a8%e7%bd%b2/%e5%bc%95%e5%85%a5jar%e5%8c%85/hadoop-eclipse-plugin-2.2.0%e4%be%9d%e8%b5%96%e5%8c%85/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/I:/%e5%ae%89%e8%a3%85%e9%83%a8%e7%bd%b2/%e5%bc%95%e5%85%a5jar%e5%8c%85/hadoop-2.7.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/F:/master/hbase-0.98.12.1-hadoop2/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2015-07-15 15:44:23,834 WARN [main] util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2015-07-15 15:44:24,915 INFO [main] client.RMProxy (RMProxy.java:createRMProxy(98)) - Connecting to ResourceManager at master/192.168.37.136:8032
2015-07-15 15:44:26,029 WARN [main] mapreduce.JobResourceUploader (JobResourceUploader.java:uploadFiles(171)) - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2015-07-15 15:44:26,102 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(283)) - Total input paths to process : 1
2015-07-15 15:44:26,421 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(201)) - number of splits:1
2015-07-15 15:44:26,436 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1173)) - fs.default.name is deprecated. Instead, use fs.defaultFS
2015-07-15 15:44:26,658 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(290)) - Submitting tokens for job: job_1436614419410_0030
2015-07-15 15:44:26,810 INFO [main] mapred.YARNRunner (YARNRunner.java:createApplicationSubmissionContext(371)) - Job jar is not present. Not adding any jar to the list of resources.
2015-07-15 15:44:26,918 INFO [main] impl.YarnClientImpl (YarnClientImpl.java:submitApplication(273)) - Submitted application application_1436614419410_0030
2015-07-15 15:44:26,952 INFO [main] mapreduce.Job (Job.java:submit(1294)) - The url to track the job: http://master:8088/proxy/application_1436614419410_0030/
2015-07-15 15:44:26,953 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1339)) - Running job: job_1436614419410_0030
2015-07-15 15:44:32,034 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1360)) - Job job_1436614419410_0030 running in uber mode : false
2015-07-15 15:44:32,037 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1367)) - map 0% reduce 0%
2015-07-15 15:44:32,066 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1380)) - Job job_1436614419410_0030 failed with state FAILED due to: Application application_1436614419410_0030 failed 2 times due to AM Container for appattempt_1436614419410_0030_000002 exited with exitCode: 1
For more detailed output, check application tracking page:http://master:8088/cluster/app/application_1436614419410_0030Then, click on links to logs of each attempt.
Diagnostics: Exception from container-launch.
Container id: container_1436614419410_0030_02_000001
Exit code: 1
Exception message: /bin/bash: line 0: fg: no job control
Stack trace: ExitCodeException exitCode=1: /bin/bash: line 0: fg: no job control
at org.apache.hadoop.util.Shell.runCommand(Shell.java:545)
at org.apache.hadoop.util.Shell.run(Shell.java:456)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:722)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:211)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Container exited with a non-zero exit code 1
Failing this attempt. Failing the application.
2015-07-15 15:44:32,102 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1385)) - Counters: 0
|


 /2
/2 







 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡




