问题导读:
1.hadoop编程需要哪些基础?
2.hadoop编程需要注意哪些问题?
3.如何创建mapreduce程序及其包含几部分?
4.如何远程连接eclipse,可能会遇到什么问题?
5.如何编译hadoop源码?


阅读此篇文章,需要些基础下面两篇文章
零基础学习hadoop到上手工作线路指导(初级篇)
零基础学习hadoop到上手工作线路指导(中级篇)
如果看过的话,看这篇不成问题,此篇讲hadoop编程篇。
hadoop编程,hadoop是一个Java框架,同时也是编程的一次革命,使得传统开发运行程序由单台客户端(单台电脑)转换为可以由多个客户端运行(多台机器)运行,使得任务得以分解,这大大提高了效率。
hadoop既然是一个Java框架,因为我们必须要懂Java,网上有大量的资料,所以学习Java不是件难事。但是学到什么程度,可能是我们零基础同学所关心的。
语言很多情况下都是相通的,如果你是学生,还处于打基础的阶段,那么难度对于你来说还是不小的。
1.初学者要求必须有理论基础,并且能够完成一个小项目,最起码能够完成几个小例子,例如图书馆里等。
初学者基本的要求:
(1)懂什么是对象、接口、继续、多态
(2)必须熟悉Java语法
(3)掌握一定的常用包
(4)会使用maven下载代码
(5)会使用eclipse,包括里面的快捷键,如何打开项目
传统程序员,因为具有丰富的编程经验,因此只要能够掌握开发工具:
(1)会使用maven下载代码
(2)会使用eclipse,包括里面的快捷键,如何打开项目
(3)简单熟悉Java语法
上面的只是基础,如果想开发hadoop,还需要懂得下面内容
(1)会编译hadoop
(2)会使用hadoop-eclipse-plugin插件,远程连接集群
(3)会运行hadoop程序。
上面列出大概的内容,下面我们具体说一些需要学习的内容。

无论是传统开发人员还是学生,零基础下面都是需要掌握的:
我们就需要进入开发了。开发零基础,该如何,咱们提供了相关的内容分别介绍下面文章
学习hadoop----java零基础学习线路指导视频(1)
这一篇我们使用什么开发工具,甚至考虑使用什么操作系统。然后就是Java基础知识篇,包括变量、函数等。
学习hadoop---Java初级快读入门指导(2)
第一篇是属于思想篇,那么这一篇属于实战篇,通过不同的方式,交给你怎么编写第一个小程序。
Java零基础:一步步教你如何使用eclipse创建项目及编写小程序实例
由于上面没有真正抽象出eclipse的使用,所以这里专门介绍了使用eclipse如何创建项目,及如何编写小程序实例
java基础:eclipse编程不得不知道的技巧
eclipse基本知识会了之后,我们在项目,这些技巧相当有用,而且经常用到

一、考虑开发环境
上面是我们打基础,有了这些基础,我们就开始学习开发hadoop了,但是我们该怎么搭建环境,我们知道Windows有32、64位之分,jdk也有,那么该如何解决,我们在window32位上需要使用32位jdk,64位则使用64位jdk,同样如果Linux则使用Linux32位于64位。
更详细,可以参考零基础利用Java开发hadoop需要考虑的问题
二、使用J2SE、J2EE
使用Java我们需要整体了解Java语言,Java包含下面三种
- J2EE java企业版,主要用于web开发
- J2SE java 标准版,主要用于WEB开发,但是缺少企业版的一些特性,一般情况下java下的应用都是指J2SE的开发。
- J2ME java 微小版,主要用于手机等的开发
因此如果我们想处理、并展示数据,可以使用J2EE,更详细参考
hadoop开发--Java零基础之J2EE、J2SE、J2ME的区别
三、对Java有了一定的认识,我们开始使用Java
1.环境变量配置
对于惯用集成环境的开发者来讲,这有点不适应,比如.net,安装开发环境vs,直接开发就好了,为啥还需要配置环境变量。
环境变量可以让我们找到jdk的命令,这个或许.net的一点好处,就是都封装起来了。别的不用关心了。对于环境变量,我们
需要配置java_home,path路径,更详细参考:
hadoop开发--Java零基础之开发工具环境变量配置
2.开发工具选择
开发工具有很多种,不同的人习惯不同,开发工具也不一样,这里列出个人认为比较常用
1.eclipse
2.MyEclipse
3.maven
更多工具参考hadoop开发—Java零基础,开发选择什么开发工具比较合适
而其中maven可以和eclipse一起使用,也可以单独使用,后面开发中它还是比较常用的,比如我们下载hadoop源码,编译hadoop,都是需要maven来完成的。
maven的学习可以参考
源码编译maven系列视频教程汇总
3.Java编译
Java可以一处编译处处运行,原因是因为jvm。编译后的效果,可以查看:
Java零基础,学习hadoop:为什么要编译Java源代码,编译后会有什么效果
4.如何打开Java项目
Java项目的开发,还是比较特别的,是通过导入的方式,折合其它比如.net项目,直接点击图标就能打开,Java项目,例如通过eclipse的import导入,详细参考下面帖子:
零基础教你如何导入Java项目到eclipse中
5.Java资源下载:
上面补充了一些基本的知识,可能还不够全面,如果缺少这方面的知识,有两种办法:
1.百度,查看视频,缺什么看什么视频
2.如果想自己什么时候,都能看,可以下载下面的资源
javaWeb图书馆管理系统源码mysql版本
Java使用hadoop开发基础:Javaweb视频共享
几百GJava文件共享
java百G内容下载:包含自学,入门,高级应用,案例等
Java基础完毕,我们终于可以开发了,其实开发也并不怎么困难,经常遇到的问题如下:
1.使用插件连接不上集群
windows下连接集有两个原因
1.用户名不一致
解决办法:
1、如果是测试环境,可以取消hadoop hdfs的用户权限检查。打开conf/hdfs-site.xml,找到dfs.permissions属性修改为false(默认为true)OK了。(1.2.1 版本只有这个方法可行),如何操作可以参考第一个问题。
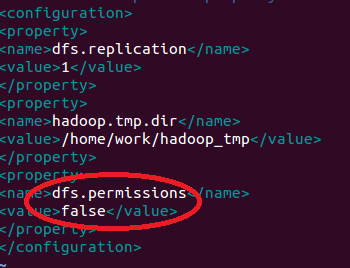
2、修改hadoop location参数,在advanced parameter选项卡中,找到hadoop.job.ugi项,将此项改为启动hadoop的用户名即可
3 修改window 机器的用户名为 hadoop 用户名。
2.运行mapreduce程序的时候,会检查权限
根据hadoop开发方式总结及操作指导
我们知道hadoop开发可以使用插件,也可以不使用插件,如果不使用插件开发可能会遇到下面问题
解决办法修改下权限就好了
windows eclipse运行mapreduce遇到权限问题该如何解决
3.缺少hadoop.dll,以及winutils.exe
(1)缺少winutils.exe回报如下错误:
Could not locate executable null \bin\winutils.exe in the hadoop binaries

windows通过hadoop-eclipse-plugin插件远程开发hadoop运行mapreduce遇到问题及解决
(2)缺少hadoop.dll
错误如下:
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决办法:
1.首先将hadoop.dll放到hadoop的bin目录下,如下图所示

2.配置hadoop home及path
path,这里使用的是绝对路径,path里面配置的是hadoop的bin路径。配置完毕,切忌重启机器
如下图所示


包及插件的下载,可以在这里面找
hadoop家族、strom、spark、Linux、flume等jar包、安装包汇总下载(持续更新)
上面总结了我们开发环境中经常遇到的问题,上面问题打了预防针,我们后面在连接的时候,就会顺利多了。
上面主要讲的window远程连接集群,还有另外一种就是Linux连接集群,这个遇到的问题不多,后面也有所涉及
开发hadoop,可以在Linux下,也可以在window下面
这里主要讲的是window下面:
该如何远程连接hadoop集群
对于不同版本不同的配置,远程连接的配置有所不同,特别是端口的配置,但是总体的步骤是差不多的,下面分别是hadoop1.X与hadoop2.X
1.插件远程连接
hadoop1.X
hadoop开发方式之一:利用插件开发指导
hadoop2.X
新手指导:Windows上使用Eclipse远程连接Hadoop进行程序开发
hadoop2.2 eclipse链接hdfs(hadoop)
配置Hadoop 2.x开发环境(Eclipse)
2.远程连接问题
连接中存在问题上面总结了一部分,比如插件、缺.dll、版本等问题
Win7中使用Eclipse连接虚拟机中的Ubuntu中的Hadoop2.4经验总结
windows 7 使用 eclipse 下hadoop应用开发环境搭建及问题总结
3.运行mapreduce
已经连接上集群,我们开始运行可以编程了,这里面我们可以操作hdfs,如下例:
hadoop实战:Java对hdfs的编程
Java创建hdfs文件实例
Java操作HDFS错误总结
当然操作hdfs,会遇到权限问题,修改hdfs-site.xml即可,我们不在重复。
除了操作hdfs上传下载文件等操作,我们还需要完成一定的功能,比如wordcount等简单功能。这里面编程完成三方面内容:
1.map函数,起到分割的作用
2.reduce函数,处理然后汇总
3.main()驱动。
4.如何带参数还需要继续Tool接口,带参数详细参考
如何编写运行带参数输入输出路径hadoop程序
(1)创建mapreduce
运行mapreduce参数参考下面:
我们首先可以完成一定的功能,功能的实现,可以参考
MapReduce初级案例(1):使用MapReduce去重
MapReduce初级案例(2):使用MapReduce数据排序
MapReduce初级案例(3):使用MapReduce实现平均成绩
通过上面的实现,这里有一个例子,可以放到项目中,直接运行,当然你需要创建数据文件,及根据自己的实际情况修改uri,也就是hdfs://。。。需要修改成自己的内容。
新手指导,该如何在开发环境中,创建mapreduce程序
如果我们对mapreduce有一个深度的了解,我们可以把大部分程序转换为mapreduce来实现,详细参考如何让传统程序转换成mapreduce
hadoop编程需要注意的问题虽然hadoop是Java语言编写的,但是其有自己的数据类型,及并且可能会遇到编码问题,同时由于mapreduce的分区,采用的是hash算发,下面的内容,可以了解一下
hadoop编程基础:数据类型介绍及与Java数据类型之间转换
eclipse 调试hadoop需要注意编码问题
hadoop基础:Java中的Hash值介绍
(2)运行mapreduce
创建完毕,我们有两种方式运行mapreduce,一种打包到集群运行,一种在eclipse中运行。
hadoop集群,如何运行Java jar包---如何运行mapreduce程序
打包集群运行:参考下面内容
java零基础:将java源码打成jar包各种方法介绍
hadoop编程:解决eclipse能运行,打包放到集群上ClassNotFoundException:经验总结
(3)运行中会遇到的问题
在开头已经说了一些经典的问题,这里在列出一些相关帖子。
1.eclipse中开发Hadoop2.x的Map/Reduce项目汇总
阐述了下面问题:
1.如何创建MR程序? 2.如何配置运行参数? 3.HADOOP_HOME为空会出现什么问题? 4.hadoop-common-2.2.0-bin-master/bin的作用是什么? 扩展: 4.winutils.exe是什么?
2.Win7 Eclipse调试Centos Hadoop2.2-Mapreduce出现问题解决方案
阐述下面问题:
1.建一个MapReduce Project,运行时发现出问题:Could not locate executable null,该如何解决?
2.Could not locate executabl ....\hadoop-2.2.0\hadoop-2.2.0\bin\winutils.exe in the Hadoop binaries.该如何解决?
3.win7下使用hadoop-eclipse-plugin插件开发添加了hadoop.dll不生效
4.通过eclipse中的Java API上传至集群为什么replication默认3份,该如何设置
5.eclipse运行出现 Call From to master:8020 failed on connection exception:
6.hadoop eclipse插件出现问题
7.Linux下面eclipse连接报错,请教大神
(4)mapreduce调试:
调试的方法有多种,这里说一种最简单、原始的一种。
记得Javascript刚开始之初是不能调试的,于是我们就采用alert的方法,看看结果是不是我们想要的,这里我们调试mapreduce采用的是类似的方法。我们通过Counter countPrint1 = context.getCounter("Map中循环strScore", “输出信息”);来输出调试信息,getCounter可以把程序里面的变量输出到Java控制台,这样就达到了调试效果。
详细参考:
Hadoop中调试(mapreduce)map与redcue信息的输出办法
当然还有其他调试方法,可以参考下面
Win7 Eclipse调试Centos Hadoop2.2-Mapreduce出现问题解决方案
调试Hadoop源代码:eclipse调试及日志打印
4.获取源码、阅读源码
获取源码可以通过git,maven等方式。
(1)maven
maven可以单独使用,也可以作为插件放在eclipse中,由于hadoop src采用的是maven的方式,所以我们需要学习和使用maven。
eclipse maven plugin 插件安装和配置及maven实战书籍下载
源码编译maven系列视频教程汇总
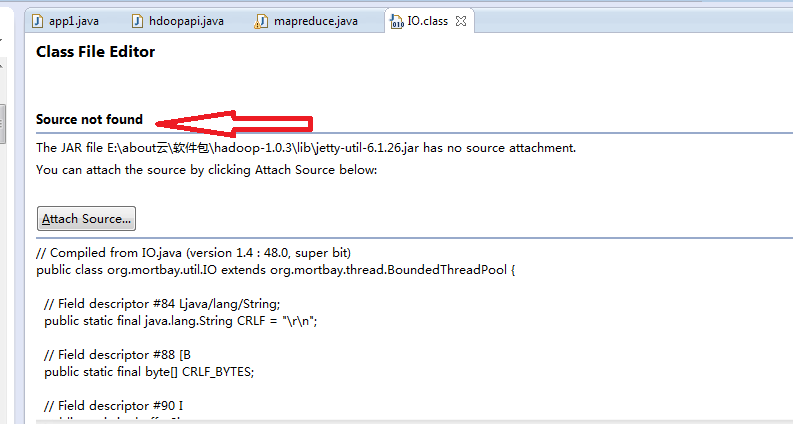
如果看了上面的内容,那么我们对maven已经算是很熟悉了,可以通过maven获取hadoop源码了,在获取的源码的时候,最起码要保持网络畅通,如何获取,以及查看hadoop源码,查看的时候,我们还需要关联一些包,否则会出现下面情况,source not found。
更多内容,详细可参考:
从零教你如何获取hadoop2.4源码并使用eclipse关联hadoop2.4源码
Eclipse查看hadoop源代码出现Source not found,是因为没有添加.zip
在eclipse中编辑hadoop2.2.0源代码指导
源码获取了,我们该如何查看阅读源码,如何通过eclipse查看类的定义,函数的实现,通过下面帖子即可达到我们的目的。
如何通过eclipse查看、阅读hadoop2.4源码
(2)其它获取源码工具git、svn
源码管理、获取网络源码工具:TortoiseSVN使用手册
Eclipse上GIT插件EGIT使用手册
5.编译hadoop源码
源码编译,刚开始还是比较复杂的,需要安装不少的软件包括maven、protobuf、CMake、ant等工具的安装,编译完毕之后,我们就可以安装了。更详细,可以查看下面内容
从零教你在Linux环境下(ubuntu)如何编译hadoop2.4
Hadoop 源代码 eclipse 编译教程
对于编译的.class文件,如果想查看源码,可以通过反编译工具实现
java的class文件反编译和Eclipse、MyEclipse反编译插件安装、使用
6.插件制作
eclipse开发,有的同学,感兴趣,想制作插件,可以查看下面内容
Hadoop2.4.0 Eclipse插件制作
Hadoop2.4.0 Eclipse插件制作及问题记录
Hadoop 2.2.0编译hadoop-eclipse-plugin插件
7.资源:
由于一些同学经常找不到安装包、插件等,这里汇总一些资源:
hadoop家族、strom、spark、Linux、flume等jar包、安装包汇总下载(持续更新)
hadoop2.4汇总:hadoop2.4插件下载、完全分布式、伪分布、eclipse插件开发大全
hadoop-eclipse-plugin-2.2.0.jar插件包分享
补充hadoop2.6 window下eclipse开发hadoop需要添加的组件:

链接:http://pan.baidu.com/s/1gd2GIND 密码:u4b4
| 

 /2
/2 


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡




