日志
彻底打通实时数据仓库该如何实现及多种技术架构解析
|
问题导读
1.实时数据仓库有哪些特点?
2.公司构建实时数据仓库有哪些好处?
3.如何构建实时数据仓库?
4.实时数据仓库本文解析了哪些架构?
越来越多的实时数据需求,需要更多的实时数据来做业务决策,例如需要依据销售情况做一个资源位的调整;同时有些活动也需要实时数据来增强与用户的互动。如果数据有实时和离线两种方案,优先考虑实时的,如果实时实现不了再考虑离线的方式。
实时数据仓库,已经被很多公司所接受,而且接触很多About云社区会员,都在筹备搭建实时数据仓库。
1.那么实时数据仓库有哪些特点:
2.公司构建实时数据仓库有哪些好处?
实时数据仓库使用者,如运营,管理层,或则老板,可以实时看到检测数据,那么实时看到检测数据,这样方便多了:
以外卖场景为例:
(1)做了营销活动,那么当前活动效果如何,如果不好,是否可以及时的补救。
(2)上线了新业务,那么新业务大家是否喜欢,根据用户的实时检测和反馈,对于新业务也可以随时调整
(3)对于订单、商家、配送如出现异常,亦可实时发现和处理
(4)对于下单的用户,亦可以根据用户喜好,实时推荐。
通过以上,面对企业想法的验证、业务异常的检测、用户的爱好推荐,我们都可以实时处理,而不是问题出现或则业务异常,导致第二天才能处理或则认识到。实时数据仓库可以让企业更高效运行。如果说离线数据仓库支持公司运营战略决策,那么实时则支持公司战略和战术决策。
3.如何构建实时数据仓库:
其实如果我们对数据仓库不了解,或则只做过离线数据仓库,可能有这么一个问题?
离线和实时他们是各自独立的,还是有关联的。从效率的角度来说,企业都不会让它们独立分开。对于实时的数据,最后还是会流入数据仓库。
如果这里不明白,我们需要进一步的说明,对于实时数据仓库来说,大多数使用的技术架构为Flink流式处理,Kafka做为存储。我们知道kafka一般是用作缓存的,数据一般都是有有效期的。所以实时数据仓库在某个阶段,数据可以设计流向离线数据仓库。
这里面如果我们真正想构建实时数据仓库,可能还有以下问题?
1.kafka作为数据仓库,它需要分层吗?该如何分层
Kafka分层是以topic来分的,表对应topic,例如形式如下:

也就是通过上面形式,我们就已经实现了kafka作为实时数据仓库。
2.如何操作Topic
我们知道Topic里面其实都是消息,如果我们想让里面的消息整合,该如何操作。这时候我们就用到了Flink Sql,Flink Sql读取Topic,然后进行各种数据操作,比如Join等。
上面我们打通了实时数据仓库存储问题,以及数据该如何操作的问题,那么具体该如何根据我们的业务来构建数据仓库?
其实我们只要理解了实时数据仓库,那么实现的方式和思路也是多种多样的,一般来说实时数仓整体框架依据数据的流向分为不同的层次,接入层会依据各种数据接入工具收集各个业务系统的数据,如埋点的业务数据或者业务后台的并购放到【kakfa】消息队列里面。消息队列的数据既是离线数仓的原始数据,也是实时计算的原始数据,这样可以保证实时和离线的原始数据是统一的。
有了源数据,在计算层经过Flink+实时计算引擎做一些加工处理,然后落地到存储层中不同存储介质当中。不同的存储介质是依据不同的应用场景来选择。框架中还有Flink和Kafka的交互,在数据上进行一个分层设计,计算引擎从Kafka中捞取数据做一些加工然后放回Kafka,这里放回的数据则可能其它分层数据。
在存储层加工好的数据会通过服务层(DWS或则DM)的两个服务:统一查询、指标管理,统一查询是通过业务方调取数据接口的一个服务,指标管理是对数据指标的定义和管理工作。通过服务层应用到不同的数据应用,数据应用可能是我们的正式产品或者直接的业务系统。
如对上面分层、数据仓库不了解,可参考下面内容
数据仓库详解:包括概念、架构及设计
https://www.aboutyun.com/forum.php?mod=viewthread&tid=21425
大数据项目之电商数仓(用户行为数据采集)(一)等系列文章。
https://www.aboutyun.com/forum.php?mod=viewthread&tid=29839
4.技术架构解析:
上面如果对数据仓库不是很了解,可能看的会比较模糊,我们继续更进一步阐述,实时数据仓库和离线数据仓库区别其实是在时间上,实时数据仓库仓库无论是采集,还是计算,都比较及时。那么具体该如何实现?比如在采集方面:可以使用一些实时采集框架canal、maxwell、EPX,为了更好的对比,那么如果离线采集,可能的插件比如Sqoop,Sqoop底层使用的是MapReduce.在计算框架方面,离线可以使用Hive,实时目前大多使用Flink。
我们在实际构建数据仓库的时候,可能面临下面问题
1.流程不清晰
2.技术选型不清晰
下面我们看几个技术架构,帮助我们选择更合适我们从纯技术角度来解析架构。
实时架构1解析:
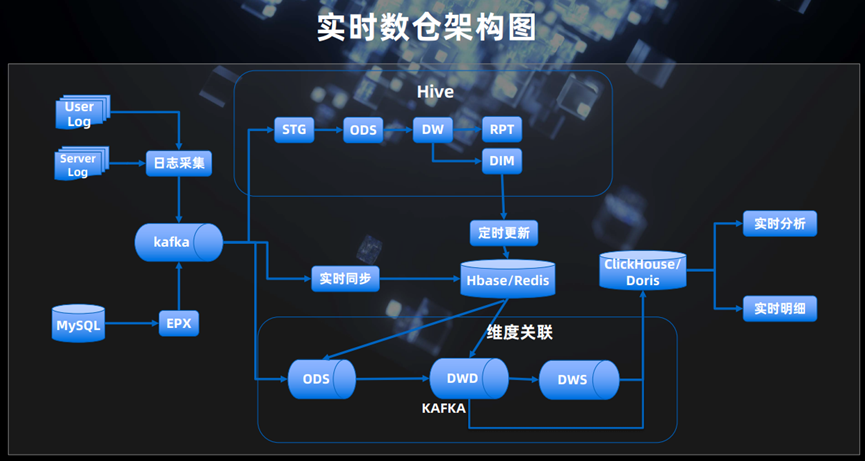
我们看到User Log、Server Log通过日志采集工具进入kafka,kafka数据分别进入,Hive和Kafka。
我们看到Hive和Kafka都进行了分层,也就是说,Hive是离线数据库,Kafka则是实时数据仓库。
HIve分层:这里需要说明的是分层其实本质每层都有对应的表。
STG:存放的是从异构的源系统集成过来数据。
ODS:最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的ETL之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。
DW:Data warehouse,数据仓库层。在这里,从ODS层中获得的数据按照主题建立各种数据模型。
RPT:是面向报表层的,包括报表查询用到的汇总表(某些查询维度较少时可以用)、明细表。
DIM:公共维度汇总层(DIM)基于维度建模理念,建立整个企业的一致性维度。
我们看到DW层和DIM层定时更新到Hbase/Redis中。
Kafka实时数据仓库:
我们看到ODS,DWD,DWS它们分别为:
DWD:数据仓库明细层(Data Warehouse Detail, DWD)
DWS:数据仓库汇总层(Data Warehouse Summery,)是数据平台的主体内容。这两个层的数据是ODS层数据经过ETL清洗、转换、加载生成的。当然大多数是把表加宽,利于分析和统计。
我们看到DWD、DWS进入ClickHouse/Doris,这里也就是我们所说的OLAP。
实时架构2解析:
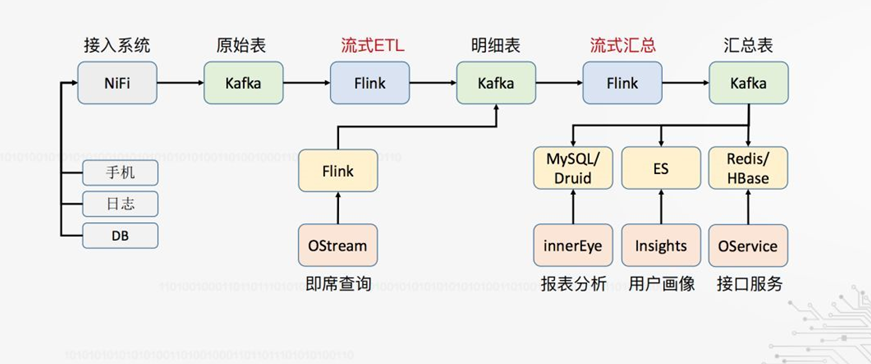
此为oppo的实时数据仓库。数据仓库采用NiFi 搜集日志,然后进入Kafka,这里原始表,应该就是ODS层,然后通过Flink ETL清洗加工等,又流入Kafka作为DWD层,这里可以即席查询,也即OLAP。Kafka明细层汇总即数据仓库的DM(ADS)层,DM层作为报表分析,用户画像、接口服务等数据源。
关于NiFi 可参考
https://www.aboutyun.com/blog-61-4370.html
实时架构3解析:
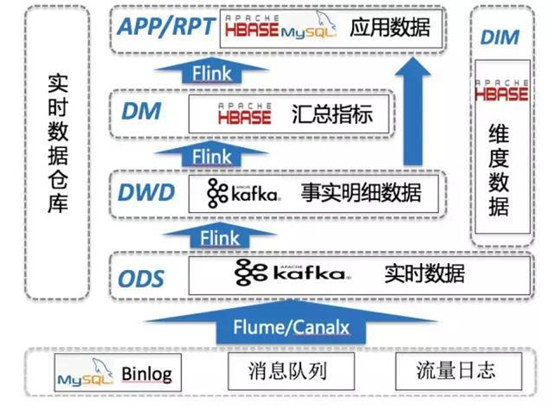
我们看此技术架构,与oppo图差异很大,但是内容基本差不多,只不过DM层替换为Hbase.这里值得注意的地方,有DIM维度层,可以与其它层数据Join。
实时架构4解析:
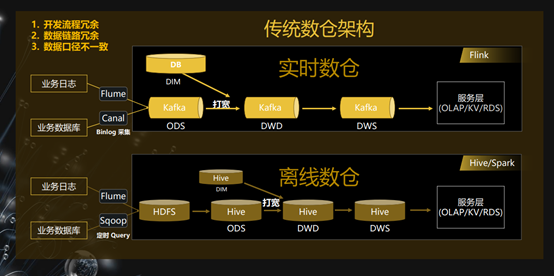
此架构离线和实时数据仓库分离,实时数据仓库使用Flink,离线数据仓库使用的是Hive/Spark。
整个流程中,在采集日志中:
实时数据仓库使用Flume和Canal
离线数据仓库使用Flume和Sqoop
存储:
实时数据仓库存储使用Kakfa
离线数据仓库存储使用Hive
分层:
实时数据仓库:ODS和DIM Join,形成宽表然后进入Kafka,形成DWD层,然后DWD进一步处理形成DWS层。
离线数据仓库:存储先进入HDFS,然后进入Hive,这里流程和实时数据仓库一样,打宽表然后形成分层等。
实时架构5解析:

这是离线和实时一体数据仓库,我们不少成员在创建实时数据仓库的时候,可能有这么一个疑问,如果数据存在Kafka,那这些数据如果过期了,该如何处理?
其实这些数据每个公司根据自己的情况,如上Kafka DWD层数据,流入离线数据仓库Hive,然后进一步处理。
上面整个流程,我们看到采集日志使用的是Flume和CDC,采集后进入实时数据仓库Kafka,然后ODS层和DIM层打宽表为DWD,DWD处理的数据分别进入离线数据仓库Hive以及Kafka的DWS层,这两条线下面相信就不用在细说了。最后DWS层为OLAP提供数据。
5.总结
从上面我们看出,无论是实时数据仓库还是离线数据仓库,数据库分层都是差不多的,关于分几层,需要根据我们的实际情况,一般来说是四到五层,京东是九层。分层的作用很多,我们认为其中每层复用和节省时间提高效率,分层起着很大的作用。
关于技术架构,其实如果上面我们都读懂了,技术架构已经不是问题。该选哪个,不该选哪个,需要考虑我们的场景、团队的知识储备等。
以上如有问题,欢迎交流。可加微信w3aboutyun,加入技术交流群。
转载注明本文链接
彻底打通实时数据仓库该如何实现及多种技术架构解析
https://www.aboutyun.com/forum.php?mod=viewthread&tid=30039

1.实时数据仓库有哪些特点?
2.公司构建实时数据仓库有哪些好处?
3.如何构建实时数据仓库?
4.实时数据仓库本文解析了哪些架构?
越来越多的实时数据需求,需要更多的实时数据来做业务决策,例如需要依据销售情况做一个资源位的调整;同时有些活动也需要实时数据来增强与用户的互动。如果数据有实时和离线两种方案,优先考虑实时的,如果实时实现不了再考虑离线的方式。
实时数据仓库,已经被很多公司所接受,而且接触很多About云社区会员,都在筹备搭建实时数据仓库。
1.那么实时数据仓库有哪些特点:
- 数据实时到达:以更快的速度到达仓库–每秒数百万个事件的流数据不断到达
- 即席查询:数据可最佳查询所需的时间更快-到达后立即进行查询,无需进行处理、聚合或压缩
- 查询速度更快:查询运行的速度更快–小型选择性查询以10或100毫秒为单位进行衡量;大型、扫描或计算繁重的查询以很高的带宽处理
- 数据更改效率高:必要时,数据变化的很快-如果由于某种原因需要校正或更新数据,则无需大量重写即可就地完成
2.公司构建实时数据仓库有哪些好处?
实时数据仓库使用者,如运营,管理层,或则老板,可以实时看到检测数据,那么实时看到检测数据,这样方便多了:
以外卖场景为例:
(1)做了营销活动,那么当前活动效果如何,如果不好,是否可以及时的补救。
(2)上线了新业务,那么新业务大家是否喜欢,根据用户的实时检测和反馈,对于新业务也可以随时调整
(3)对于订单、商家、配送如出现异常,亦可实时发现和处理
(4)对于下单的用户,亦可以根据用户喜好,实时推荐。
通过以上,面对企业想法的验证、业务异常的检测、用户的爱好推荐,我们都可以实时处理,而不是问题出现或则业务异常,导致第二天才能处理或则认识到。实时数据仓库可以让企业更高效运行。如果说离线数据仓库支持公司运营战略决策,那么实时则支持公司战略和战术决策。
3.如何构建实时数据仓库:
其实如果我们对数据仓库不了解,或则只做过离线数据仓库,可能有这么一个问题?
离线和实时他们是各自独立的,还是有关联的。从效率的角度来说,企业都不会让它们独立分开。对于实时的数据,最后还是会流入数据仓库。
如果这里不明白,我们需要进一步的说明,对于实时数据仓库来说,大多数使用的技术架构为Flink流式处理,Kafka做为存储。我们知道kafka一般是用作缓存的,数据一般都是有有效期的。所以实时数据仓库在某个阶段,数据可以设计流向离线数据仓库。
这里面如果我们真正想构建实时数据仓库,可能还有以下问题?
1.kafka作为数据仓库,它需要分层吗?该如何分层
Kafka分层是以topic来分的,表对应topic,例如形式如下:
也就是通过上面形式,我们就已经实现了kafka作为实时数据仓库。
2.如何操作Topic
我们知道Topic里面其实都是消息,如果我们想让里面的消息整合,该如何操作。这时候我们就用到了Flink Sql,Flink Sql读取Topic,然后进行各种数据操作,比如Join等。
上面我们打通了实时数据仓库存储问题,以及数据该如何操作的问题,那么具体该如何根据我们的业务来构建数据仓库?
其实我们只要理解了实时数据仓库,那么实现的方式和思路也是多种多样的,一般来说实时数仓整体框架依据数据的流向分为不同的层次,接入层会依据各种数据接入工具收集各个业务系统的数据,如埋点的业务数据或者业务后台的并购放到【kakfa】消息队列里面。消息队列的数据既是离线数仓的原始数据,也是实时计算的原始数据,这样可以保证实时和离线的原始数据是统一的。
有了源数据,在计算层经过Flink+实时计算引擎做一些加工处理,然后落地到存储层中不同存储介质当中。不同的存储介质是依据不同的应用场景来选择。框架中还有Flink和Kafka的交互,在数据上进行一个分层设计,计算引擎从Kafka中捞取数据做一些加工然后放回Kafka,这里放回的数据则可能其它分层数据。
在存储层加工好的数据会通过服务层(DWS或则DM)的两个服务:统一查询、指标管理,统一查询是通过业务方调取数据接口的一个服务,指标管理是对数据指标的定义和管理工作。通过服务层应用到不同的数据应用,数据应用可能是我们的正式产品或者直接的业务系统。
如对上面分层、数据仓库不了解,可参考下面内容
数据仓库详解:包括概念、架构及设计
https://www.aboutyun.com/forum.php?mod=viewthread&tid=21425
大数据项目之电商数仓(用户行为数据采集)(一)等系列文章。
https://www.aboutyun.com/forum.php?mod=viewthread&tid=29839
4.技术架构解析:
上面如果对数据仓库不是很了解,可能看的会比较模糊,我们继续更进一步阐述,实时数据仓库和离线数据仓库区别其实是在时间上,实时数据仓库仓库无论是采集,还是计算,都比较及时。那么具体该如何实现?比如在采集方面:可以使用一些实时采集框架canal、maxwell、EPX,为了更好的对比,那么如果离线采集,可能的插件比如Sqoop,Sqoop底层使用的是MapReduce.在计算框架方面,离线可以使用Hive,实时目前大多使用Flink。
我们在实际构建数据仓库的时候,可能面临下面问题
1.流程不清晰
2.技术选型不清晰
下面我们看几个技术架构,帮助我们选择更合适我们从纯技术角度来解析架构。
实时架构1解析:
我们看到User Log、Server Log通过日志采集工具进入kafka,kafka数据分别进入,Hive和Kafka。
我们看到Hive和Kafka都进行了分层,也就是说,Hive是离线数据库,Kafka则是实时数据仓库。
HIve分层:这里需要说明的是分层其实本质每层都有对应的表。
STG:存放的是从异构的源系统集成过来数据。
ODS:最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的ETL之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。
DW:Data warehouse,数据仓库层。在这里,从ODS层中获得的数据按照主题建立各种数据模型。
RPT:是面向报表层的,包括报表查询用到的汇总表(某些查询维度较少时可以用)、明细表。
DIM:公共维度汇总层(DIM)基于维度建模理念,建立整个企业的一致性维度。
我们看到DW层和DIM层定时更新到Hbase/Redis中。
Kafka实时数据仓库:
我们看到ODS,DWD,DWS它们分别为:
DWD:数据仓库明细层(Data Warehouse Detail, DWD)
DWS:数据仓库汇总层(Data Warehouse Summery,)是数据平台的主体内容。这两个层的数据是ODS层数据经过ETL清洗、转换、加载生成的。当然大多数是把表加宽,利于分析和统计。
我们看到DWD、DWS进入ClickHouse/Doris,这里也就是我们所说的OLAP。
实时架构2解析:
此为oppo的实时数据仓库。数据仓库采用NiFi 搜集日志,然后进入Kafka,这里原始表,应该就是ODS层,然后通过Flink ETL清洗加工等,又流入Kafka作为DWD层,这里可以即席查询,也即OLAP。Kafka明细层汇总即数据仓库的DM(ADS)层,DM层作为报表分析,用户画像、接口服务等数据源。
关于NiFi 可参考
https://www.aboutyun.com/blog-61-4370.html
实时架构3解析:
我们看此技术架构,与oppo图差异很大,但是内容基本差不多,只不过DM层替换为Hbase.这里值得注意的地方,有DIM维度层,可以与其它层数据Join。
实时架构4解析:
此架构离线和实时数据仓库分离,实时数据仓库使用Flink,离线数据仓库使用的是Hive/Spark。
整个流程中,在采集日志中:
实时数据仓库使用Flume和Canal
离线数据仓库使用Flume和Sqoop
存储:
实时数据仓库存储使用Kakfa
离线数据仓库存储使用Hive
分层:
实时数据仓库:ODS和DIM Join,形成宽表然后进入Kafka,形成DWD层,然后DWD进一步处理形成DWS层。
离线数据仓库:存储先进入HDFS,然后进入Hive,这里流程和实时数据仓库一样,打宽表然后形成分层等。
实时架构5解析:
这是离线和实时一体数据仓库,我们不少成员在创建实时数据仓库的时候,可能有这么一个疑问,如果数据存在Kafka,那这些数据如果过期了,该如何处理?
其实这些数据每个公司根据自己的情况,如上Kafka DWD层数据,流入离线数据仓库Hive,然后进一步处理。
上面整个流程,我们看到采集日志使用的是Flume和CDC,采集后进入实时数据仓库Kafka,然后ODS层和DIM层打宽表为DWD,DWD处理的数据分别进入离线数据仓库Hive以及Kafka的DWS层,这两条线下面相信就不用在细说了。最后DWS层为OLAP提供数据。
5.总结
从上面我们看出,无论是实时数据仓库还是离线数据仓库,数据库分层都是差不多的,关于分几层,需要根据我们的实际情况,一般来说是四到五层,京东是九层。分层的作用很多,我们认为其中每层复用和节省时间提高效率,分层起着很大的作用。
关于技术架构,其实如果上面我们都读懂了,技术架构已经不是问题。该选哪个,不该选哪个,需要考虑我们的场景、团队的知识储备等。
以上如有问题,欢迎交流。可加微信w3aboutyun,加入技术交流群。
转载注明本文链接
彻底打通实时数据仓库该如何实现及多种技术架构解析
https://www.aboutyun.com/forum.php?mod=viewthread&tid=30039
最新经典文章,欢迎关注公众号





 /2
/2 