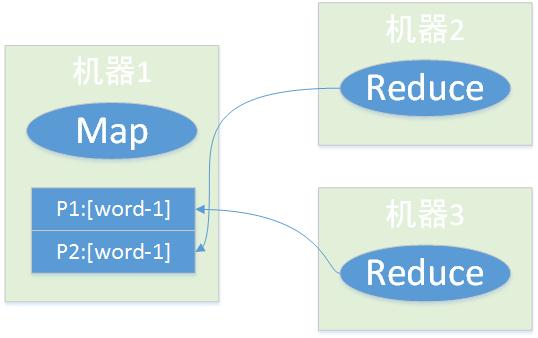
| 拉去对应分区的内容,在map正在运行的时候reduce已经开始运行(reduce在map运行之后多长时间运行可以在mapred-site.xml进行配置)。可参考此片文章:http://blog.163.com/songyalong11 ... 1897201410710401077 |
| 应该是拉取对应分区的键值对记录,否则的话,partition又有什么意义呢? |
pengsuyun 发表于 2015-1-30 08:31 赞同,map输出之后,会被不同的reduce拉取 |
| 我觉得reduce是要在map完成后再去拉取数据。而且在拉取的时候,是拉取的整个map数据,map输出的数据格式是 <key,{value1,value2...}>,在聚合生成分区号之前以及之后都有一次排序。这仅仅是我的个人观点 |
| map处理完毕之后,就输出了,个人认为是拉取自己关心的内容。不相关的不会去拉取 |
 /2
/2 
Copyright © 2001-2025 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000