wjhdtx ЗЂБэгк 2015-4-9 08:15 /opt/hadoop/bin/hadoop namenode -format |
БОЬћзюКѓгЩ wjhdtx гк 2015-4-9 08:55 БрМ wjhdtx ЗЂБэгк 2015-4-8 17:29 ЪЧ ./bin/hdfsnamenode ЈCformat ЛЙЪЧ datanode -formatЃЌДѓМвЭЈЙ§cmАВзАЭъcdhЃЌЛЙЕУЪжЖЏИёЪНЛЏЃП |
yongjian3311 ЗЂБэгк 2015-4-8 16:11 datanode -format етИіУќСюКУЯёУЛгажДааАЩЃЌЖМЪЧдкcmЕФweb uiЩЯВйзїЁЃ СэЭтЃЌХфСЫЪБМфЭЌВНЃЌвВУЛгУЃЌдкФЧвЛЬЈХмзївЕЕФЛњЦїЩЯЃЌвВжЛгаmapШЮЮёдкХмЃЌМДжЛгавЛИіYarnChildНјГЬЁЃ жЎЧАгУapache hadoop2.5.1ЩЯЃЌСНЬЈnodemanagerЩЯХмСЫМИИіYarnChildНјГЬЁЃ ВЛжЊЕРcdhдкФФЩшжУСЫЩЯЯоТ№ЃПзэСЫ |
БОЬћзюКѓгЩ pig2 гк 2015-4-8 18:57 БрМ wjhdtx ЗЂБэгк 2015-4-8 16:17 ЪдЪдетаЉАЩЃК ЁЁЃЈ1ЃЉ ФЌШЯЧщПіЯТЃЌИїИіНкЕуЕФИКдиВЛОљКтЃЈШЮЮёЪ§ФПВЛЭЌЃЉЃЌгаЕФНкЕуКмЖрШЮЮёдкХмЃЌгаЕФУЛгаШЮЮёЃЌдѕбљШУИїИіНкЕуШЮЮёЪ§ФПОЁПЩФмОљКтФиЃП ЁЁЁЁД№ЃК ФЌШЯЧщПіЯТЃЌзЪдДЕїЖШЦїДІгкХњЕїЖШФЃЪНЯТЃЌМДвЛИіаФЬјЛсОЁПЩФмЖрЕФЗжХфШЮЮёЃЌетбљЃЌгХЯШЗЂЫЭаФЬјЙ§РДЕФНкЕуНЋЛсАбШЮЮёСьЙтЃЈЧАЬсЃКШЮЮёЪ§ФПдЖаЁгкМЏШКПЩвдЭЌЪБдЫааЕФШЮЮёЪ§СПЃЉЃЌЮЊСЫБмУтИУЧщПіЗЂЩњЃЌПЩвдАДеевдЯТЫЕУїХфжУВЮЪ§ЃК ЁЁЁЁШчЙћВЩгУЕФЪЧfair schedulerЃЌПЩдкyarn-site.xmlжаЃЌНЋВЮЪ§yarn.scheduler.fair.max.assignЩшжУЮЊ1ЃЈФЌШЯЪЧ-1,ЃЉ ЁЁЁЁШчЙћВЩгУЕФЪЧcapacity schedulerЃЈФЌШЯЕїЖШЦїЃЉЃЌдђВЛФмХфжУЃЌФПЧАИУЕїЖШЦїВЛДјИКдиОљКтжЎРрЕФЙІФмЁЃ ЁЁЁЁЕБШЛЃЌДгhadoopМЏШКРћгУТЪНЧЖШПДЃЌИУЮЪЬтВЛЫуЮЪЬтЃЌвђЮЊвЛАуЧщПіЯТЃЌгУЛЇШЮЮёЪ§ФПвЊдЖдЖДѓгкМЏШКЕФВЂЗЂДІРэФмСІЕФЃЌвВОЭЪЧЫЕЃЌЭЈГЃЧщПіЯТЃЌМЏШКЪБПЬДІгкУІТЕзДЬЌЃЌУЛгаНкЕувЛжБПеЯазХЁЃ ЁЁЁЁЃЈ2ЃЉФГИіНкЕуЩЯШЮЮёЪ§ФПЬЋЖрЃЌзЪдДРћгУТЪЬЋИпЃЌдѕУДПижЦвЛИіНкЕуЩЯЕФШЮЮёЪ§ФП? ЁЁЁЁД№ЃКвЛИіНкЕуЩЯдЫааЕФШЮЮёЪ§ФПжївЊгЩСНИівђЫиОіЖЈЃЌвЛИіЪЧNodeManagerПЩЪЙгУЕФзЪдДзмСПЃЌвЛИіЪЧЕЅИіШЮЮёЕФзЪдДашЧѓСПЃЌБШШчвЛИі NodeManagerЩЯПЩгУзЪдДЮЊ8 GBФкДцЃЌ8 cpuЃЌЕЅИіШЮЮёзЪдДашЧѓСПЮЊ1 GBФкДцЃЌ1cpuЃЌдђИУНкЕузюЖрдЫаа8ИіШЮЮёЁЃ ЁЁЁЁNodeManagerЩЯПЩгУзЪдДЪЧгЩЙмРэдБдкХфжУЮФМўyarn-site.xmlжаХфжУЕФЃЌЯрЙиВЮЪ§ШчЯТЃК ЁЁЁЁyarn.nodemanager.resource.memory-mbЃКзмЕФПЩгУЮяРэФкДцСПЃЌФЌШЯЪЧ8096 ЁЁЁЁyarn.nodemanager.resource.cpu-vcoresЃКзмЕФПЩгУCPUЪ§ФПЃЌФЌШЯЪЧ8 ЁЁЁЁЖдгкMapReduceЖјбдЃЌУПИізївЕЕФШЮЮёзЪдДСППЩЭЈЙ§вдЯТВЮЪ§ЩшжУЃК ЁЁЁЁmapreduce.map.memory.mbЃКЮяРэФкДцСПЃЌФЌШЯЪЧ1024 ЁЁЁЁmapreduce.map.cpu.vcoresЃКCPUЪ§ФПЃЌФЌШЯЪЧ1 ЁЁЁЁзЂЃКвдЩЯетаЉХфжУЪєадЕФЯъЯИНщЩмПЩВЮПМЮФеТЃКHadoop YARNХфжУВЮЪ§ЦЪЮі(1)ЁЊRMгыNMЯрЙиВЮЪ§ЁЃ ЁЁЁЁФЌШЯЧщПіЃЌИїИіЕїЖШЦїжЛЛсЖдФкДцзЪдДНјааЕїЖШЃЌВЛЛсПМТЧCPUзЪдДЃЌФуашвЊдкЕїЖШЦїХфжУЮФМўжаНјааЯрЙиЩшжУЃЌОпЬхПЩВЮПМЮФеТЃКHadoop YARNХфжУВЮЪ§ЦЪЮі(4)ЁЊFair SchedulerЯрЙиВЮЪ§КЭHadoop YARNХфжУВЮЪ§ЦЪЮі(5)ЁЊCapacity SchedulerЯрЙиВЮЪ§ЁЃ Hadoop YARNГЃМћЮЪЬтвдМАНтОіЗНАИ |
langke93 ЗЂБэгк 2015-4-8 16:08 бЙЫѕЁЂФкДцЁЂcpuЃЌвдМАЦфЫћmapКЭreduceжДааЙ§ГЬжаЕФЯрЙиВЮЪ§ЃЌСЫНтmapreduceЙ§ГЬЃЌШЛКѓЕїгХЃЌБШШчmapreduce.task.io.sort.mbЁЂmapreduce.tasktracker.http.threadsЁЂmapreduce.reduce.shuffle.parallelcopiesЕШЕШЁЃ |
yongjian3311 ЗЂБэгк 2015-4-8 16:11 МЏШКУЛЮЪЬтЃЌЖМЦєЖЏСЫЃЌзївЕвВХмЙ§ЁЃ |
|
1. жЎЧАФмГЩЙІЦєЖЏећИіМЏШКТ№ЃП 2. ЛсВЛЛсЪЧвђЮЊdatanode -format жЎКѓЩњГЩЕФШЮЮёIDИњзгНкЕуЕФАцБОВЛвЛбљЫљвдЙиСЊВЛЩЯЦєЖЏВЛГЩЙІЃП |
|
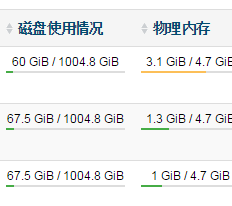
ТЅжїПЩвдЫЕЫЕдѕУДгХЛЏЕФЃЌФкДцЪЧдѕУДгХЛЏЕФЃЌЪЧЗёЩшжУЙ§БпНчВтЪдЁЃ ПЩвдЩшжУзуЙЛаЁЃЈБШЗННгНќЮЊ0ЃЉЃЌШЛКѓдкТ§Т§ЕїећЃЌЯраХФмгагаЪеЛё |
 /2
/2 
Copyright © 2001-2025 AboutдЦ Powered by Discuz! X3.4 Licensed Discuz Team.
МђЪщ /
![]() ОЉICPБИ2020039040КХ
ОЉICPБИ2020039040КХ
![]() МђЪщЭјОйБЈЕчЛАЃК021-34700000
МђЪщЭјОйБЈЕчЛАЃК021-34700000