NEOGX 发表于 2016-9-1 18:31 感谢你的回复,可能跟你说的有些出入了,因为最开始搭环境时,在window下eclipse中跑wordcount的时候,输出输出可以使用本地文件系统的。问题我自己解决了,是我的粗心大意导致的,具体请看下面楼层。再次感谢你的回复 |
nextuser 发表于 2016-9-1 18:04 谢谢你的回复,hadoop环境是2.5.2版本,eclipse关联的源码包也是2.5.2的,并没有提交到集群中去,只是在eclipse中运行调试啦。已经解决问题了,是我的粗心大意,不过还是很感谢你的回复!!(问题解决请看下面楼层) |
|
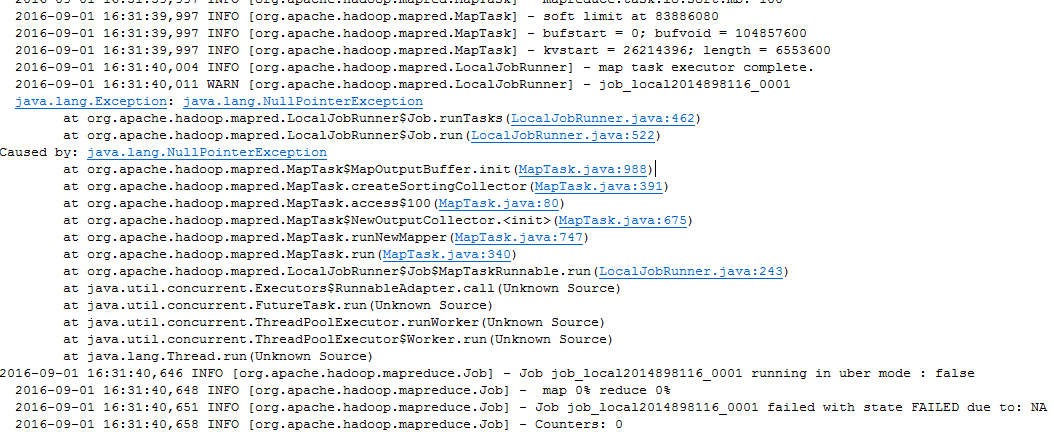
好像没有把封装的样本,导入到map reduce main中 如果提交到集群,这些包也都需要配置下 |
|
//设置输入输出流 FileInputFormat.setInputPaths(job, new Path("E:\\qyzfile\\大数据工作室\\smoteData")); FileOutputFormat.setOutputPath(job, new Path("E:\\qyzfile\\大数据工作室\\smoteOutput")); 最好使用hdfs路径 |
|
代码是哪个版本的,提交的集群又是哪个版本的 |
 /2
/2 
Copyright © 2001-2025 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000