|
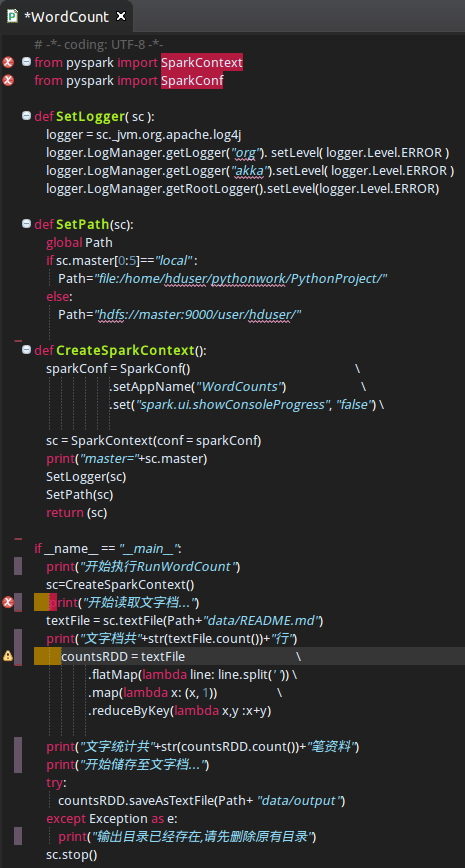
书只是一方面,可能写的不全。多找此类资料 另外确保所有的包都加载进来,然后代码没有问题。 下面是一个例子,可对比参考 WordCount代码如下: [mw_shl_code=python,true]如何运行Python版本的WordCount import sys from operator import add from pyspark import SparkContext if __name__ == "__main__": if len(sys.argv) != 2: print >> sys.stderr, "Usage: wordcount <file>" exit(-1) sc = SparkContext(appName="PythonWordCount") lines = sc.textFile(sys.argv[1], 1) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counts.collect() for (word, count) in output: print "%s: %i" % (word, count) [/mw_shl_code] 输入文件路径可以是本地也可以是HDFS上文件,命令如下: [hadoop@centos spark-1.0.0-bin-hadoop1]$ bin/spark-submit --master spark://centos.host1:7077 /home/hadoop/project/WordCount.py /home/hadoop/temp/word.txt [hadoop@centos spark-1.0.0-bin-hadoop1]$ bin/spark-submit --master spark://centos.host1:7077 /home/hadoop/project/WordCount.py hdfs://centos.host1:9000/user/hadoop/data/wordcount/001/word.txt 可以看到控制台有如下结果: spark: 1 hbase: 2 hive: 2 zookeeper: 1 hadoop: 4 pig: 1 |
|
不能加载本地包,1.环境变量是否配置了 2.包是否存在 3.可以debug下,推荐参考 https://community.hortonworks.co ... mote-debugging.html |
 /2
/2 
Copyright © 2001-2025 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000