luo360 发表于 2019-12-26 16:35 你是怎么判断丢失的,最好贴出来,看看是什么原因。需要判断,到底是元数据的原因,还是数据丢失造成的。如果是元数据,是否备份了,是否有Secondary NameNode或则备用节点等。 楼主可看下图 
|
|
现在怀疑修复数据的时候是不是服务不行,而不是真的数据库丢失了,1年前的数据库也丢失,按照道理不会,不知道有人试过现有的集群(dfs.datanode.data.dir)和(dfs.namenode.name.dir)数据直接挂在一个新的集群上,就不格式化新集群,不知道行不? 哪位大神可以指点下 |
| 现在手工启动,集群看似正常,但是通过hadoop fsck /命令检查,发现10几万的文件丢失,后面使用hdfs debug recoverLease -path $line -retries 2 命令修复,检查发现无效,确认无效,估计这批数据真是无法找回来了 |
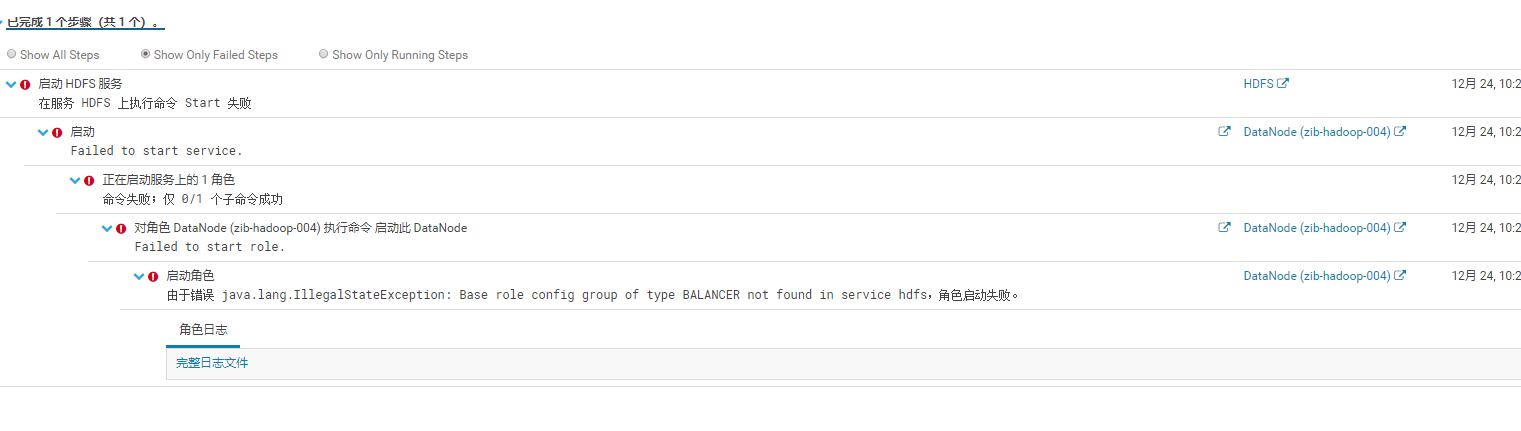
luo360 发表于 2019-12-25 14:47 namenode看看日志启动报什么错误 |
| 现在就是手工启动了,CM页面上也监听不到DATANODE的状态,而且提示很多快坏了,NAMENODE手工启动还报错,基本上这个集群处于废弃完全不能用的情况 |
luo360 发表于 2019-12-25 09:30 那就是没有了,不过这个应该不影响启动的。 实在不行,采用下面方法: 1.手工启动hdfs,也就是直接通过hdfs命令启动 2.cloudera其实只是对hadoop的封装而已,Balancers命令应该也可以实现启动的。 |
|
最好一开始就使用免费版,避免造成这样的情况。 楼主可以参考下面官网的内容,看能否在配置下 https://docs.cloudera.com/docume ... _hdfs_balancer.html 
|
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000