|
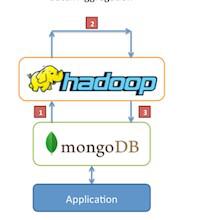
MongoDB+Hadoop Connector CURRENT RELEASE: 1.0.0 The Mongo+Hadoop Connector (for brevitys sake, we’ll refer to it as mongo-hadoop in this documentation) is a series of plugins for the Apache Hadoop Platform to allow connectivity to MongoDB. This connectivity takes the form of allowing both reading MongoDB data into Hadoop (for use in MapReduce jobs as well as other components of the Hadoop ecosystem), as well as writing the results of Hadoop jobs out to MongoDB. A forthcoming release will also allow for reading and writing static BSON files (ala mongodump / mongorestore) to allow offline batching; commonly, users find this to be a beneficial feature to run analytics against backup data. At this time, we support the “core” Hadoop APIs (now known as Hadoop Common), in the form of mongo-hadoop-core. There is additionally support for other pieces of the Hadoop Ecosystem, including Pig for ETL and Streaming for running Mongo+Hadoop jobs with Python (future releases will support additional scripting languages such as Ruby). Although it is not dependent upon Hadoop, we also provide a connector for the Flume distributed logging system. 具体可以参考下面的官网地址: http://api.mongodb.org/hadoop/MongoDB%2BHadoop+Connector.html https://github.com/mongodb/mongo-hadoop |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000