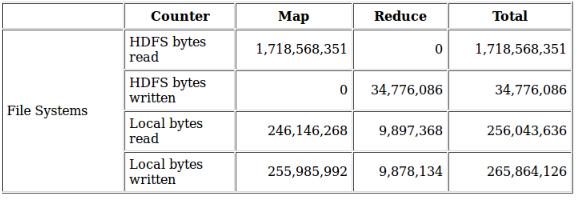
| 很好的总结资料 |
|
1.map会将已经产生的部分结果先写入到该buffer中.buffer大小可以通过那个参数来设置? io.sort.mb 2.如何降低map的split的次数? 把io.sort.mb调大,那么map在整个计算过程中spill的次数就势必会降低 3.map中的数据什么情况下会写入磁盘?spill是什么? map输出超出一定阈值(比如100M),那么map就必须将该buffer中的数据写入到磁盘中去,这个过程在mapreduce中叫做spill。 4.map其实是当buffer被写满到一定程度(比如80%)时,就开始进行spill有由那个参数来决定? map其实是当buffer被写满到一定程度(比如80%)时,就开始进行spill。这个阈值也是由一个job的配置参数来控制,即io.sort.spill.percent,默认为0.80或80%。 5.通过哪个参数可以控制map中间结果是否使用压缩的? 控制map中间结果是否使用压缩的参数为:mapred.compress.map.output(true/false)。 6.reduce包含几个阶段,是每个reduce都必须包含? reduce包含三个阶段,并不是所有阶段我们必须只定义。 7.Reduce task在做shuffle的过程是什么样子的?如何调整多个并行map个数的下载? Reduce task在做shuffle时,实际上就是从不同的已经完成的map上去下载属于自己这个reduce的部分数据,由于map通常有许多个,所以对一个reduce来说,下载也可以是并行的从多个map下载,这个并行度是可以调整的,调整参数为:mapred.reduce.parallel.copies(default 5)。 8.reduce的数据是否全部来源磁盘,如何调整使用内存? 当reduce task真正进入reduce函数的计算阶段的时候,有一个参数也是可以调整reduce的计算行为。也就是:mapred.job.reduce.input.buffer.percent(default 0.0)。由于reduce计算时肯定也是需要消耗内存的,而在读取reduce需要的数据时,同样是需要内存作为buffer,这个参数是控制,需要多少的内存百分比来作为reduce读已经sort好的数据的buffer百分比。默认情况下为0,也就是说,默认情况下,reduce是全部从磁盘开始读处理数据。如果这个参数大于0,那么就会有一定量的数据被缓存在内存并输送给reduce,当reduce计算逻辑消耗内存很小时,可以分一部分内存用来缓存数据,反正reduce的内存闲着也是闲着。 |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000