本帖最后由 尘世随缘 于 2015-4-5 13:49 编辑
统计需求如下: 1、按用户统计给定时间范围内的每种optype操作记录总数 2、按单位统计给定时间范围内的每种optype操作记录总数
重新编辑下:
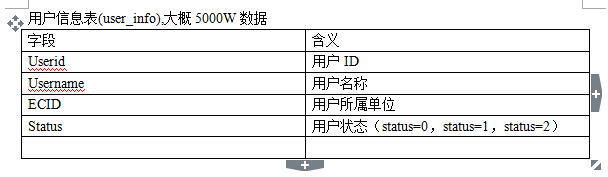
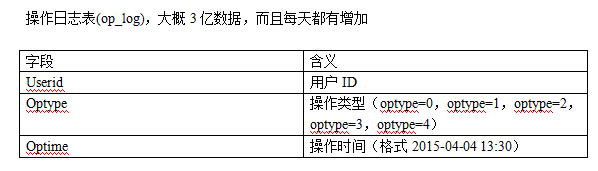
目前执行的过程如下: 查询Select * from user_Info where status=0 or status=2的结果放入一个队列,userList 然后循环队列 For(UserInfo userinfo:userList){ Int c1=select count(1) from op_log where Optype=0 and userid=userinfo.getUserID() and Optime》时间 and Optime<时间; Int c2=select count(1) from op_log where Optype=1 and userid=userinfo.getUserID() and Optime》时间 and Optime<时间;
Int c3=select count(1) from op_log where Optype=2 and userid=userinfo.getUserID() and Optime》时间 and Optime<时间; ; Int c4=select count(1) from op_log where Optype=4 and userid=userinfo.getUserID() and Optime》时间 and Optime<时间; ; } 然后统计结果插入数据库user_op_cout表 现在打算把数据通过hive查询,请问hive这种操作需要如何写SQL/
| 
 /2
/2 

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡






