|
问题导读
1.如何避免反复部署集群?
2.快照的作用是什么?
3.缓存服务器能起到什么作用?

学习大数据、云技术,我们首先应该掌握的是部署,通过部署,我们认识hadoop、openstack等大数据、云技术。
所以部署是我们入门的第一步。
在我们学习的过程中,部署异常是经常遇到的问题,当然如果比较喜欢专研或则非要找出哪里出错了,此文不要适合,本人适合人群,对于错误,无法找到,或则部署混乱,不得不重新部署。这里交给大家,如何最大限度的提高效率。
1.虚拟机快照
来源:
使用虚拟机搭建hadoop、openstack集群必备基础知识:虚拟机快照
我们刚从零基础知识学会搭建集群,学会了Linux知识,学会了Java基础。然后我们开始搭建集群。
搭建hadoop集群
搭建hbase集群
搭建storm
搭建spark集群
在搭建集群的过程中,遇到了各种问题,然后不断的重复开始,不断重复搭建,废了很长时间搭建快要成功的时候,前面都正确安装,但是因为某一个操作,却把环境搞坏了。比如hadoop搭建成功,hbase却失败了。但是又找不出原因。Java环境配置正确了,却因为ssh不成功,然后不断的修改。坏境坏了,该如何办?
如果我们刚开始学习,会不断的重复搭建环境,然后花费大量的时间,在搭建集群上,那么有没有更好的办法。答案是有的,就是----创建虚拟机快照。
那么该具体如何操作:
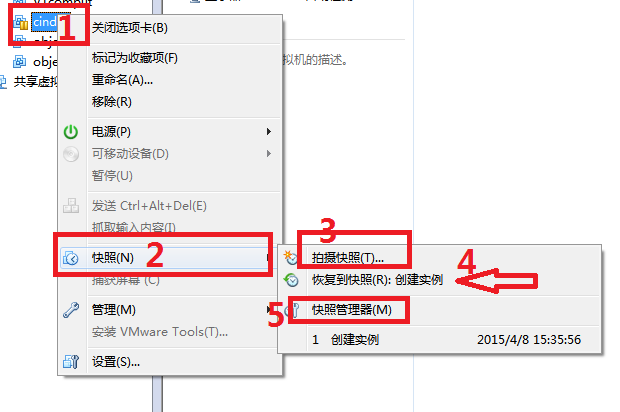
首先我们看到1处虚拟机,右键弹出右侧菜单,然后看到快照。
3.拍摄快照
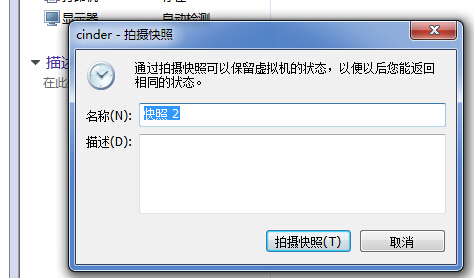
点击拍摄快照后,弹出下图,输入名称,快照就做好了。如果后面配置遇到问题,恢复快照即可。
4.恢复到快照
上面做好了快照,这里就可以恢复到某个快照了。
5.快照管理器
单击快照管理,就看到了备份的快照,如果备份了多个就能看到多个。可以恢复到任意一个备份的快照
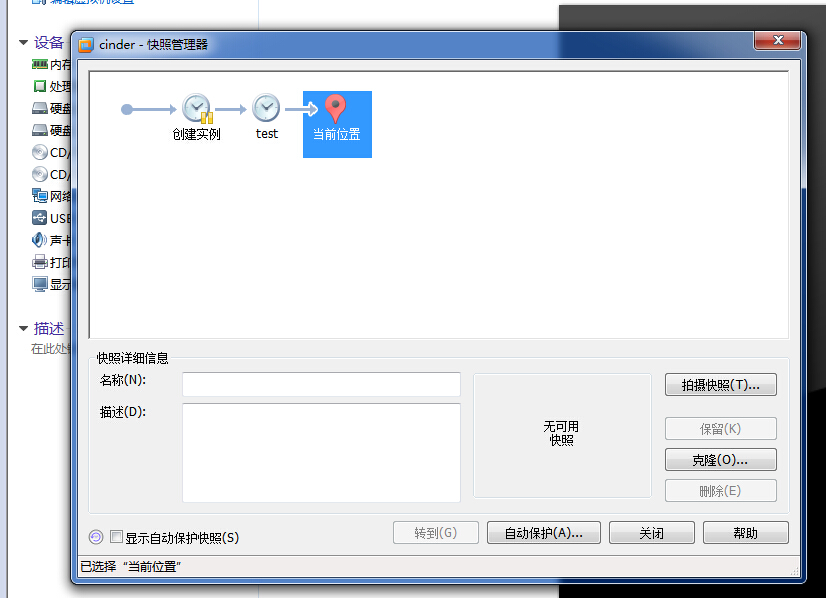
以上有的朋友可能也知道的,但是合理的使用快照,可以提高搭建集群的效率
2.搭建缓存服务器
这里以ubuntu14.04为例:
源服务器名称可能不太准确,意思是创建内网自己的私服,这样只要有Ubuntu通过该私服下载安装过软件,私服都会缓存,下一个Ubuntu的请求就直接从缓存中获取。
首先安装apt-cacher
- apt-get install apt-cacher
装的过程中选择Daemon方式。
装完后,/etc/default/apt-cacher 文件内容应该如下:
复制代码
所以服务应该已经启动了。
到/etc/apt-cacher/apt-cacher.conf文件中修改一行配置,允许任何客户端访问:
复制代码
重启服务
- service apt-cacher restart
然后打开网页:http://your_ip:3142/apt-cacher
看到页面就说明服务器正常启动了。
在/etc/hosts文件中添加一行,可以帮助找到chrome依赖的dl.google.com
- 203.208.45.206 dl.google.com
在客户端的ubuntu机器上,创建文件 /etc/apt/apt.conf文件或者/etc/apt/apt.conf.d/01proxy文件
内容如下:
- Acquire::http::Proxy "http://your_server:3142";
然后运行apt-get update, 为了确认真的起作用。可以查看apt-cacher的日志,到服务器上查看目录下的日志文件
/var/log/apt-cacher
这里以openstack为例:
服务器ip地址为10.0.0.100:

客户端配置:
在客户端的ubuntu机器上,创建文件 /etc/apt/apt.conf文件或者/etc/apt/apt.conf.d/01proxy文件
内容如下:
[mw_shl_code=bash,true]Acquire::http::Proxy "http://10.0.0.100:3142";[/mw_shl_code]
然后运行apt-get update, 为了确认真的起作用。可以查看apt-cacher的日志,到服务器上查看目录下的日志文件
/var/log/apt-cacher
监控:

| 
 /2
/2 

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡




