问题导读
1.Hadoop文件系统shell与Linux shell有哪些相似之处?
2.如何改变文件所属组?
3.如何改变hdfs的文件权限?
4.如何查找hdfs文件,并且不区分大小写?

概述
文件系统 (FS) shell 包括各种类似的命令直接与 Hadoop Distributed File System (HDFS)交互。hadoop也支持其它文件系统,比如 Local FS, HFTP FS, S3 FS, 和 其它的. FS shell被下面调用:
[mw_shl_code=bash,true]bin/hadoop fs <args>[/mw_shl_code]
所有的FS shell命令带有URIs路径参数。The URI 格式是://authority/path。对 HDFS文件系统,scheme是hdfs。其中scheme和 authority参数都是可选的
如果没有指定,在文件中使用默认scheme.一个hdfs文件或则目录比如 /parent/child,可以是 hdfs://namenodehost/parent/child 或则简化为/parent/child(默认配置设置成指向hdfs://namenodehost).大多数FS shell命令对应 Unix 命令.每个命令都有不同的描述。将错误信息发送到标准错误输出和输出发送到stdout。
appendToFile【添加文件】
用法: hadoop fs -appendToFile <localsrc> ... <dst>添加单个src,或则多个srcs从本地文件系统到目标文件系统。从标准输入读取并追加到目标文件系统。
- hadoop fs -appendToFile localfile /user/hadoop/hadoopfile
- hadoop fs -appendToFile localfile1 localfile2 /user/hadoop/hadoopfile
- hadoop fs -appendToFile localfile hdfs://nn.example.com/hadoop/hadoopfile
- hadoop fs -appendToFile - hdfs://nn.example.com/hadoop/hadoopfile Reads the input from stdin.
返回代码:
返回 0成功返回 1 错误
cat
用法: hadoop fs -cat URI [URI ...]
将路径指定文件的内容输出到stdout
例子:
- hadoop fs -cat hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -cat file:///file3 /user/hadoop/file4
返回代码:
返回 0成功返回 1 错误
checksum
用法: hadoop fs -checksum URI
返回 checksum 文件信息
例子:
- hadoop fs -checksum hdfs://nn1.example.com/file1
- hadoop fs -checksum file:///etc/hosts
chgrp
用法: hadoop fs -chgrp [-R] GROUP URI [URI ...]
改变文件所属组. 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
chmod
用法: hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI ...]
更改文件的权限. 使用-R 将使改变在目录结构下递归进行。 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
chown
用法: hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
更改文件的所有者. 使用-R 将使改变在目录结构下递归进行。 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
copyFromLocal
用法: hadoop fs -copyFromLocal <localsrc> URI
类似put命令, 需要指出的是这个限制是本地文件
选项:
copyToLocal
用法: hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
与get命令类似, 除了限定目标路径是一个本地文件外。
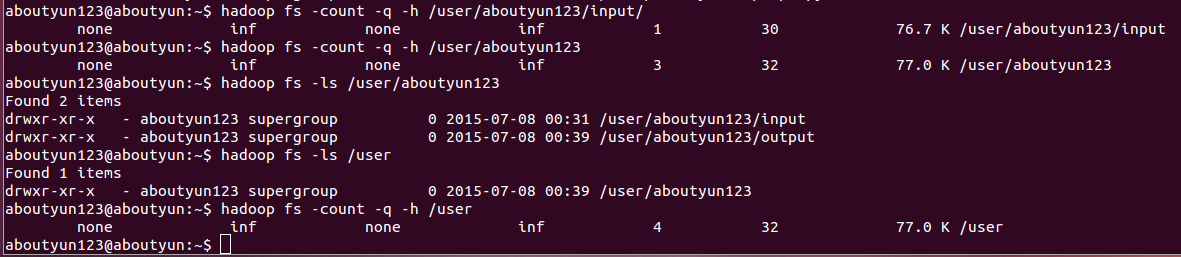
count
用法: hadoop fs -count [-q] [-h] [-v] <paths>统计目录个数,文件和目录下文件的大小。输出列:DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
【目录个数,文件个数,总大小,路径名称】
输出列带有 -count -q 是: QUOTA, REMAINING_QUATA, SPACE_QUOTA, REMAINING_SPACE_QUOTA, DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
【配置,其余指标,空间配额,剩余空间定额,目录个数,文件个数,总大小,路径名称】
The -h 选项,size可读模式.
The -v 选项显示一个标题行。
Example:
- hadoop fs -count hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -count -q hdfs://nn1.example.com/file1
- hadoop fs -count -q -h hdfs://nn1.example.com/file1
- hdfs dfs -count -q -h -v hdfs://nn1.example.com/file1
返回代码:
返回 0成功返回 1 错误
cp
用法: hadoop fs -cp [-f] [-p | -p[topax]] URI [URI ...] <dest>复制文件,这个命令允许复制多个文件到一个目录。
‘raw.*’ 命名空间扩展属性被保留
(1)源文件和目标文件支持他们(仅hdfs)
(2)所有的源文件和目标文件路径在 /.reserved/raw目录结构下。
决定是否使用 raw.*命名空间扩展属性依赖于-P选项
选项:
- -f 选项如果文件已经存在将会被重写.
- -p 选项保存文件属性 [topx] (timestamps, ownership, permission, ACL, XAttr). 如果指定 -p没有参数, 保存timestamps, ownership, permission. 如果指定 -pa, 保留权限 因为ACL是一个权限的超级组。确定是否保存raw命名空间属性取决于是否使用-p决定
例子:
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回代码:
返回 0成功返回 1 错误
createSnapshot
查看 HDFS Snapshots Guide.
deleteSnapshot
查看 HDFS Snapshots Guide.
df【查看还剩多少hdfs空间】
用法: hadoop fs -df [-h] URI [URI ...]
显示剩余空间
选项:
- -h 选项会让人更加易读 (比如 64.0m代替 67108864)
Example:
- hadoop dfs -df /user/hadoop/dir1

du
用法: hadoop fs -du [-s] [-h] URI [URI ...]显示给定目录的文件大小及包含的目录,如果只有文件只显示文件的大小
选项:
- -s 选项汇总文件的长度,而不是现实单个文件.
- -h 选项显示格式更加易读 (例如 64.0m代替67108864)
例子:
- hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://nn.example.com/user/hadoop/dir1
返回代码:
返回 0成功返回 1 错误

dus
用法: hadoop fs -dus <args>
显示统计文件长度
注意:这个命令已被启用, hadoop fs -du -s即可
expunge
用法: hadoop fs -expunge
清空垃圾回收站. 涉及 HDFS Architecture Guide 更多信息查看回收站特点
find
用法: hadoop fs -find <path> ... <expression> ...查找与指定表达式匹配的所有文件,并将选定的操作应用于它们。如果没有指定路径,则默认查找当前目录。如果没有指定表达式默认-print
下面主要表达式:
如果
值为TRUE如果文件基本名匹配模式使用标准的文件系统组合。如果使用-iname匹配不区分大小写。
- -print
-print0Always
值为TRUE. 当前路径被写至标准输出。如果使用 -print0 表达式, ASCII NULL 字符是追加的.
下面操作:
- expression -a expression
expression -and expression
expression expression
and运算符连接两个表达式,如果两个字表达式返回true,则返回true.由两个表达式的并置暗示,所以不需要明确指定。如果第一个失败,则不会应用第二个表达式。
例子:
hadoop fs -find / -name test -print
返回代码:
返回 0成功返回 1 错误

get
用法: hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>复制文件到本地文件。
复制文件到本地文件系统. 【CRC校验失败的文件复制带有-ignorecrc选项(如翻译有误欢迎指正)】
Files that fail the CRC check may be copied with the -ignorecrc option.
文件CRC可以复制使用CRC选项。
例子:
- hadoop fs -get /user/hadoop/file localfile
- hadoop fs -get hdfs://nn.example.com/user/hadoop/file localfile
返回代码:
返回 0成功返回 1 错误
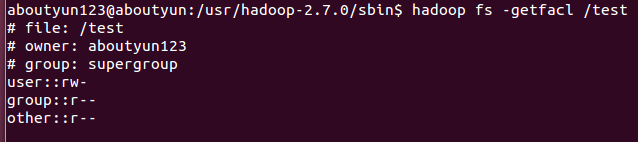
getfacl
用法: hadoop fs -getfacl [-R] <path>
显示访问控制列表(ACL)的文件和目录. 如果一个目录有默认的ACL, getfacl 也显示默认的ACL.
选项:
- -R: 递归目录和列出所有文件的ACLs.
- path: 文件或目录列表。
例子:
- hadoop fs -getfacl /file
- hadoop fs -getfacl -R /dir
返回代码:
返回 0成功返回 非0 错误
getfattr
用法: hadoop fs -getfattr [-R] -n name | -d [-e en] <path>
显示文件和目录扩展属性名字和值[如果有的话]
选项:
- -R: 递归显示文件和目录属性.
- -n name: Dump the named extended attribute value.
- -d: Dump all extended attribute values associated with pathname.
- -e encoding: 检索后的值进行编码。 有效的编码是 “text”, “hex”, and “base64”. 值编码作为文本字符串是用双引号括起来的(“),
值编码作为16进制和64进制,前缀分别为 0x 和 0s
例子:
- hadoop fs -getfattr -d /file
- hadoop fs -getfattr -R -n user.myAttr /dir
返回代码:
返回 0成功返回 非0 错误
getmerge
用法: hadoop fs -getmerge <src> <localdst> [addnl]
源目录和目标文件作为输入和连接文件合并到本地目标文件。addnl选项可以设置在文件末尾添加一个换行符。
help
用法: hadoop fs -help
返回使用输出。
ls
用法: hadoop fs -ls [-d] [-h] [-R] [-t] [-S] [-r] [-u] <args>
选项:
- -d: 目录被列为纯文件。
- -h: 文件格式变为易读 (例如 67108864显示 64.0m).
- -R: 递归子目录列表中。
- -t: 按修改时间排序输出(最近一次)。
- -S: 按文件大小排序输出。
- -r: 倒序排序
- -u: 对使用时间显示和排序而不是修改时间
文件返回下面信息:
[mw_shl_code=bash,true]permissions number_of_replicas userid groupid filesize modification_date modification_time filename
权限 副本数 用户名 所属组 文件大小 修改日期 修改时间 文件名[/mw_shl_code]
目录返回下面信息
权限 用户 所属组 修改日期 修改时间 目录名
目录内的文件默认按文件名排序
例子:
- hadoop fs -ls /user/hadoop/file1
退出代码:
返回0成功,返回-1错误
lsr
用法: hadoop fs -lsr <args>
ls递归
注意: 这个命令被启用的,替换为hadoop fs -ls -R
mkdir
用法: hadoop fs -mkdir [-p] <paths>
以URI的路径作为参数并创建目录。
选项:
- -p 选项与Linux -p功能一样,会创建父目录
例子:
- hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
- hadoop fs -mkdir hdfs://nn1.example.com/user/hadoop/dir hdfs://nn2.example.com/user/hadoop/dir
退出代码:
返回0成功,-1错误
moveFromLocal
用法: hadoop fs -moveFromLocal <localsrc> <dst>
类似put命令,但是它是本地源文件复制后被删除
moveToLocal
用法: hadoop fs -moveToLocal [-crc] <src> <dst>
显示 “Not implemented yet” 消息
mv
用法: hadoop fs -mv URI [URI ...] <dest>移动文件,这个命令允许移动多个文件到某个目录
例子:
- hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -mv hdfs://nn.example.com/file1 hdfs://nn.example.com/file2 hdfs://nn.example.com/file3 hdfs://nn.example.com/dir1
退出代码:
返回0成功,-1错误
put
用法: hadoop fs -put <localsrc> ... <dst>
复制单个或则多个源文件到目标系统文件。从stdin读取输入并写入到目标文件系统。
- hadoop fs -put localfile /user/hadoop/hadoopfile
- hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
- hadoop fs -put localfile hdfs://nn.example.com/hadoop/hadoopfile
- hadoop fs -put - hdfs://nn.example.com/hadoop/hadoopfile 从stdin读取输入。
退出代码:
返回0成功,-1错误
renameSnapshot
See HDFS Snapshots Guide.
rm
用法: hadoop fs -rm [-f] [-r |-R] [-skipTrash] URI [URI ...]
删除指定的参数文件。
选项:
- -f 选项 如果该文件不存在,则该选项将不显示诊断信息或修改退出状态以反映错误。
- -R选项递归删除目录下任何内容
- -r与-R效果一样
- -skipTrash选项绕过垃圾回收器,如果启用,将会立即删除指定文件。这是非常有用对于超过配额的目录
例子:
- hadoop fs -rm hdfs://nn.example.com/file /user/hadoop/emptydir
退出代码:
返回0成功,-1错误
rmdir
用法: hadoop fs -rmdir [--ignore-fail-on-non-empty] URI [URI ...]
删除目录
选项:
- --ignore-fail-on-non-empty: 当使用通配符,一个目录还包含文件,不会失败.
例子:
- hadoop fs -rmdir /user/hadoop/emptydir
rmr
用法: hadoop fs -rmr [-skipTrash] URI [URI ...]
递归删除
说明:这个命令被弃用了,而是使用hadoop fs -rm -r
setfacl
用法: hadoop fs -setfacl [-R] [-b |-k -m |-x <acl_spec> <path>] |[--set <acl_spec> <path>]
设置访问控制列表(ACL)的文件和目录。
选项:
- -b:移除所有除了基本的ACL条目。用户、组和其他的条目被保留为与权限位的兼容性。
- -k:删除默认的ACL。
- -R: 递归应用于所有文件和目录的操作。
- -m:修改ACL。新的项目添加到ACL,并保留现有的条目。
- -x: 删除指定的ACL条目。其他保留ACL条目。
- --set:完全替换ACL,丢弃所有现有的条目。acl_spec必须包括用户,组,和其他有权限位的兼容性。
- acl_spec:逗号分隔的ACL条目列表。
- path:修改文件或目录。
例子:
- hadoop fs -setfacl -m user:hadoop:rw- /file
- hadoop fs -setfacl -x user:hadoop /file
- hadoop fs -setfacl -b /file
- hadoop fs -setfacl -k /dir
- hadoop fs -setfacl --set user::rw-,user:hadoop:rw-,group::r--,other::r-- /file
- hadoop fs -setfacl -R -m user:hadoop:r-x /dir
- hadoop fs -setfacl -m default:user:hadoop:r-x /dir
退出代码:
返回0成功,非0错误
以上需要开启acl:
开启acls,配置hdfs-site.xml
[mw_shl_code=bash,true]vi etc/hadoop/hdfs-site.xml
<property>
<name>dfs.namenode.acls.enabled</name>
<value>true</value>
</property>[/mw_shl_code]
setfattr
用法: hadoop fs -setfattr -n name [-v value] | -x name <path>
设置一个文件或目录的扩展属性名和值。
选项:
-b: 移除所有的条目除了基本的ACL条目。用户、组和其他的条目被保留为与权限位的兼容性。
-n name:扩展属性名。
-v value:扩展属性值。有三种不同编码值,如果该参数是用双引号括起来的,则该值是引号内的字符串。如果参数是前缀0x或0X,然后作为一个十六进制数。如果参数从0或0,然后作为一个base64编码。
-x name: 移除所有属性值
path: 文件或则路径
例子:
- hadoop fs -setfattr -n user.myAttr -v myValue /file
- hadoop fs -setfattr -n user.noValue /file
- hadoop fs -setfattr -x user.myAttr /file
退出代码:
返回0成功,非0错误
setrep
用法: hadoop fs -setrep [-R] [-w] <numReplicas> <path>
更改文件的备份. 如果是一个目录,会递归改变目录下文件的备份。
选项:
-w标识,要求备份完成,这可能需要很长时间。
-R标识,是为了兼容,没有实际效果
例子:
- hadoop fs -setrep -w 3 /user/hadoop/dir1
退出代码:
返回0成功,非0错误
stat
用法: hadoop fs -stat [format] <path> ...按指定格式打印文件/目录的打印统计。
格式接受文件块 (%b), 类型 (%F), groutp拥有者 (%g), 名字 (%n), block size (%o), replication (%r), 用户拥有者(%u), 修改日期 (%y, %Y). %y 显示 UTC 日期如 “yyyy-MM-dd HH:mm:ss” 和 %Y 1970年1月1日以来显示毫秒UTC. 如果没有指定, 默认使用%y.
例子:
- hadoop fs -stat "%F %u:%g %b %y %n" /file
退出代码:
返回0成功
返回-1错误
tail
用法: hadoop fs -tail [-f] URI
显示文件内容,最后千字节的文件发送到stdout,
选项:
- f选项将输出附加数据随着文件的增长,如同Unix
例子:
退出代码:
返回0成功
返回-1错误
test
用法: hadoop fs -test -[defsz] URI
选项:
-d:如果路径是一个目录,返回0
-e:如果路径已经存在,返回0
-f: 如果路径是一个文件,返回0
-s:如果路径不是空,返回0
-z:如果文件长度为0,返回0
例子:
- hadoop fs -test -e filename
text
用法: hadoop fs -text <src>
一个源文件,以文本格式输出文件。允许的格式是zip和textrecordinputstream。
touchz
用法: hadoop fs -touchz URI [URI ...]
创建一个零长度的文件。
例子:
- hadoop fs -touchz pathname
退出代码:返回0成功,-1error
truncate
用法: hadoop fs -truncate [-w] <length> <paths>
截断指定文件模式指定的长度匹配的所有文件。
选项:
-w 选项需要等待命令完成块恢复。如果没有-w选项,在恢复的过程中可能是未闭合的
例子:
- hadoop fs -truncate 55 /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -truncate -w 127 hdfs://nn1.example.com/user/hadoop/file1
usage
用法: hadoop fs -usage command
返回单个命令的帮助。
相关文章
hadoop入门-第一章General:第一节单节点伪分布
hadoop入门-第一章General:第二节集群配置
hadoop入门-第一章General:第三节Hadoop初级入门之命令指南
hadoop入门-第一章General:第四节文件系统shell
hadoop入门-第一章General:第五节hadoop的兼容性说明
hadoop入门-第一章General:第六节开发人员和用户接口指南:hadoop接口分类
hadoop入门-第一章General:第七节Hadoop 文件系统 API :概述
hadoop入门-第二章common:第一节hadoop 本地库 指南
hadoop入门-第二章common:第二节hadoop代理用户 -超级用户代理其它用户
hadoop入门-第二章common:第三节机架智能感知
hadoop入门-第二章common:第四节安全模式说明
hadoop入门-第二章common:第五节服务级别授权指南
hadoop入门-第二章common:第六节Hadoop HTTP web-consoles认证机制
hadoop入门-第二章common:第七节Hadoop Key管理服务器(KMS) - 文档集
hadoop入门:第三章HDFS文档概述(一)
hadoop入门:第三章HDFS文档概述(二)
hadoop入门:第四章mapreduce文档概述
hadoop入门:第五章MapReduce REST APIs文档概述
hadoop入门:第六章YARN文档概述
hadoop入门:第七章YARN REST APIs
hadoop入门:第八章hadoop兼容文件系统
hadoop入门:第九章hadoop认证
hadoop入门:第十章hadoop工具
hadoop入门:第十一章hadoop配置
|

 /2
/2 

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡




