53. 以下哪项关于决策树的说法是错误的 (C)
A. 冗余属性不会对决策树的准确率造成不利的影响
B. 子树可能在决策树中重复多次
C. 决策树算法对于噪声的干扰非常敏感
D. 寻找最佳决策树是NP完全问题
55. 以下哪些算法是基于规则的分类器 (A)
A. C4.5
B. KNN
C. Na?ve Bayes
D. ANN
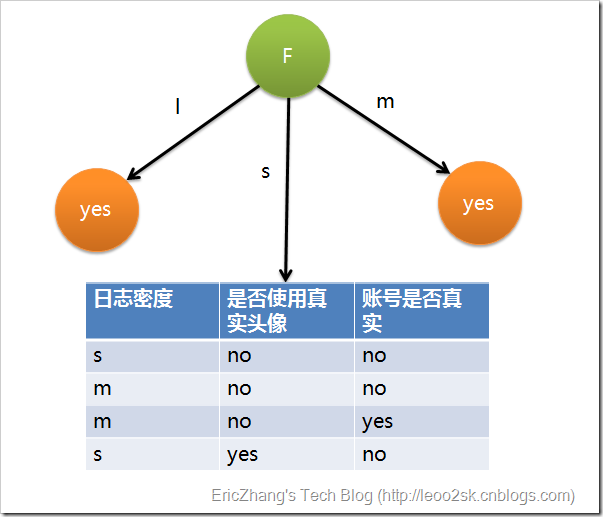
ID3算法 从信息论知识中我们直到,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。下面先定义几个要用到的概念。 设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为: 其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。 现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为: 而信息增益即为两者的差值: ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素:
其中s、m和l分别表示小、中和大。 设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。 因此日志密度的信息增益是0.276。 用同样方法得到H和F的信息增益分别为0.033和0.553。 因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示: 在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。 上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法: 先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。 C4.5算法 ID3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gain ratio)的信息增益扩充,试图克服这个偏倚。 C4.5算法首先定义了“分裂信息”,其定义可以表示成: 其中各符号意义与ID3算法相同,然后,增益率被定义为:
ANN简介: 人工神经网络提供了一种普遍而且实用的方法从样例中学习实数、离散值或向量法函数。它适合具有以下特征的问题: >实例是用很多“属性-值”对表示的; >目标函数的输出可能是离散值、实数值或者由若干实数属性或离散属性组成的向量; >训练数据可能包含错误; >可容忍长时间的训练; >可能需要快速求出目标函数值; >人类能否理解学到的目标函数并不重要。
| 
 /2
/2 


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡



