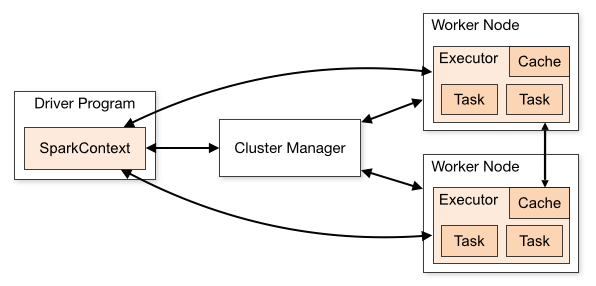
客气了,我研究spark时间也不久1、DAG本身就是一个抽象的关系描述,标明数据的来源
2、个人理解,思路不是很清晰,大概说明的层级的关系。
个人对RDD\stages的理解:
1、存在多级RDD,从上层开始顺序执行,每个RDD都产生了一个stages
2、而RDD可以由一个action或一个、多个Transformation组成
3、不会推导出“不存在直接关系的同一个RDD”是否重复执行
[mw_shl_code=scala,true]val l1=l.map(a => (a,1))
val l2=l.map(a => (a,2))
val l3=l1.join(l2)[/mw_shl_code]
三个语句都不是action类型的,所以生成了三个rdd
l1: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[31] at map at <console>:26
l2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[32] at map at <console>:26
l3: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[35] at join at <console>:30
测试:1:执行l1.collect
会发现DAG只有文件到MAP的操作

测试2:执行l3.collec会发现出现2个MAP一个collect,但是DAG中并没有MAP相关的描述


测试3:重复l3.collect会发现只有一个collect任务,不过发现ID直接从20跳到23(由于是在同一个shell下,RDD临时缓存吧)

在复杂一些,为了避免内存溢出吧map改简单点
[mw_shl_code=scala,true]val l1=l.map(a => (a,1))
val l2=l.map(a => (a,1))
val l3=l1.join(l2)
val l4=l1.join(l2)
val l5=l3.join(l4)[/mw_shl_code]
测试4:l5.collect

存在5个任务,collect更为复杂,依然没有MAP,且执行了2次(每次是2个MAP)

|

 /2
/2 

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡