本帖最后由 desehawk 于 2017-7-4 16:59 编辑
个人理解:
[mw_shl_code=scala,true]List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data);
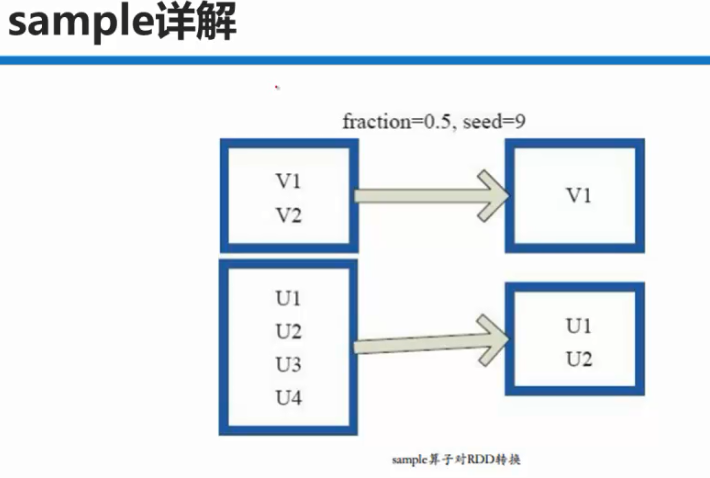
//false 是伯努利分布 (元素可以多次采样);0.2 采样比例;100 随机数生成器的种子
JavaRDD<Integer> sampleRDD = javaRDD.sample(false,0.2,100);
System.out.println("sampleRDD~~~~~~~~~~~~~~~~~~~~~~~~~~" + sampleRDD.collect());
//true 是柏松分布;0.2 采样比例;100 随机数生成器的种子
JavaRDD<Integer> sampleRDD1 = javaRDD.sample(false,0.2,100);
System.out.println("sampleRDD1~~~~~~~~~~~~~~~~~~~~~~~~~~" + sampleRDD1.collect());[/mw_shl_code]
如上面两个例子:
首先true和false采用的是不同的算法。第二个应该是抽出的比例,猜测应该抽取多少样本。第三个,不太清楚,估计可能是在100个中,随机产生,如果中了就算一个样本。
至于他的用途,由于这个没有实际的场景,所以可能会不懂。比如我们检测产品的质量,可以采用上面算法。随机抽取,之后,看看质量如何,如果好,说明这个产品不错。
|

 /2
/2 

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡