本帖最后由 howtodown 于 2018-6-28 11:48 编辑
问题导读
1.什么情况下执行优化验证测试?
2.优化验证测试的一般形式是什么?
3.教直升机复杂的飞行动作如何进行优化验证的?

上一篇吴恩达《Machine_Learning_Yearning》中文版:第36-43章 训练数据
http://www.aboutyun.com/forum.php?mod=viewthread&tid=24730
44 优化验证测试假设你正在构建一个语音识别系统,该系统通过输入一个音频片段A,并为每一个可能的输出句子S计算得分

。例如,你可以试着估计 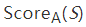 = P(S|A) ,表示句子S是正确输出的转录的概率,其中 A 是给定的输入音频。
给定某种方法能够计算 后,你仍然需要找到一个英文句子S来使之最大化:
要如何去计算上面的 呢?假设在英文中共有 5000 个词汇,对于长度为 N 的句子,则有

种搭配,多到根本无法一一列举。因此,需要使用一种近似搜索算法,努力去找到能够优化(最大化) 的那个S。有一种叫做 “定向搜索” 的搜索算法,在搜索过程中仅保留最优的K个候选项(在本章中你并不需要了解该算法的细节)。类似这样的算法并不足以保证能够找到满足条件的S来最大化 .
假设有一个音频片段记录着某人说的:“我爱机器学习。”但你的系统输出的却是不正确的 “我爱机器人。”,它没能够输出正确的转录。造成该误差的可能原因有两种:
搜索算法存在问题。 近似搜索算法没能够找到最大化 的那个S. 目标(得分函数)存在问题。 我们对 = P(S|A)的估计并不准确。尤其在此例中,我们的得分函数 没能辨认出 “我爱机器学习” 是正确的转录。
对应不同的失败原因,你需要优先考虑的工作方向也将很不一样。如果原因 1 导致了问题,你应该改进搜索算法。如果原因 2 导致了问题,你应该在评估学习算法的函数 上面多花些心思。
面对这种情况,一些研究人员将决定研究搜索算法;其他人则努力去找到更好的ScoreA(S). 但是,除非你知道其中哪一个是造成误差的潜在原因,否则你的努力可能会被浪费掉。怎么样才能更系统地决定要做什么呢?
让我们用

表示实际的输出 “我爱机器人”,用S*表示正确的输出 “我爱机器学习” 。为了搞清楚上面的 1 或 2 是否存在问题,你可以执行 优化验证测试(Optimization Verification test): 首先计算

和

,接着比较他们的大小。有两种可能:
情况1: > >  在这种情况下,你的学习算法正确地给了S* 一个比Sout 更高的分数。尽管如此,我们的近似搜索算法选择了Sout而不是S* . 则表示你的近似搜索算法没能够找到最大化ScoreA(S) 的那个S . 此时优化验证测试告诉你,搜索算法存在着问题,应该花时间研究。例如,你可以尝试增加定向搜索的搜索宽度。
情况2: ≤ 在这种情况下,计算ScoreA(.) 的方式是错误的:它没有给正确的输出S* 比实际输出Sout 一个相同或更高的分数。优化验证测试告诉你,目标(得分函数)存在问题。因此,你应该专注于改进你的算法对不同的句子S学习或近似出得分ScoreA(S) 的方式。
我们上面的讨论集中于某个单一的样本 A上,想要在实践中运用优化验证测试,你需要在开发集中检测这些误差样本。对于每一个误差样本,你都需要测试是否有ScoreA(S*) > ScoreA(Sout) . 开发集中所有满足该不等式的样本都将被标记为优化算法自身所造成的误差,而满足不等式ScoreA(S*) ≤ ScoreA(Sout) 的样本将被记为是计算得分ScoreA(.) 造成的误差。
假设你最终发现 95% 的误差是得分函数ScoreA(.) 造成的,而仅有 5% 的误差是由优化算法造成的。现在你应该知道了,无论你如何改进你的优化程序, 实际上也只会消除误差中的 5% 左右。因此,你应该专注于改进你的得分函数 ScoreA(.) 。
45 优化验证测试的一般形式你可以在如下情况运用优化验证测试,给定输入 x,且知道如何计算Scorex(y)来表示y对输入x的响应好坏。此外,你正在使用一种近似算法来尽可能地找到arg maxy Scorex(y),但却怀疑该搜索算法有时候并不能找到最大值。在我们先前提到的语音识别的例子中,x=A代表某个音频片段,y=S代表输出的转录。
假设y*是 “正确的” 输出,而算法输出了yout. 此时的关键在于测量是否有Scorex(y*) > Scorex(yout) . 如果该不等式成立,我们便可以将误差归咎于优化算法。(请参考前一章的内容,以确保你理解这背后的逻辑。)否则,我们将误差归咎于Scorex(y) 的计算方式。
让我们再看一个例子:假设你正在构建一个中译英的机器翻译系统,输入一个中文句子 C ,并计算出每一个可能的翻译句子E的得分ScoreC(E),例如,你可以使用ScoreC(E) = P(E|C),表示给定输入句子C,对应翻译句子为E的概率。
你的算法将通过计算下面的公式来进行句子的翻译:
然而所有可能的英语句子 E 构成的集合太大了,所以你将依赖于启发式搜索算法。
假设你的算法输出了一个错误的翻译Eout,而不是正确的翻译E*. 优化验证测试会要求你计算是否有ScoreC(E*) > ScoreC(Eout) . 如果这个不等式成立,表明ScoreC(.) 正确地辨认E* 是一个更好的输出;因此你可以将把这个误差归咎于近似搜索算法。否则,你可以将这个误差归咎于ScoreC(.) 的计算方式。
在人工智能领域,这是一种非常常见的 “设计模式”,首先要学习一个近似的得分函数Scorex(.) ,然后使用近似最大化算法。如果你能够发现这种模式,就能够使用优化验证测试来理解造成误差的来源。
46 强化学习举例假设你正在用机器学习来教直升机复杂的飞行动作。下面是一张延时照片,照片上是一台电脑控制器的直升机正在引擎关闭的情况下执行着陆。
这被称为“自旋”策略,即使引擎意外故障了,它也允许直升机着陆。这也是人类飞行员经常进行的训练。而你的目标是使用一种学习算法,让直升机通过一个轨迹T安全地着陆。
要应用强化学习策略,你必须设计一个 “奖励函数” R(.) ,它给出一个分数来衡量每一个可能轨迹T的好坏。例如,如果T导致直升机坠毁,那么奖励也许是 R(T) = -1,000 ,这是一个巨大的负反馈;而一个导致安全着陆的轨迹 T可能会产生一个正的R(T) 值,它的精确值取决于着陆过程的平稳程度。奖励函数R(.) 通常是人为选择的,以量化不同轨迹T的理想程度。它必须权衡考虑着陆的颠簸程度,直升机是否降落在理想的位置,乘客的降落体验等因素。设计一个好的建立函数并非易事。
给定一个奖励函数R(T) ,强化学习算法的工作是控制直升机,使其达到maxT R(T). 然而,强化学习算法原理内部有许多近似操作,可能无法成功实现这种最大化需求。
假设你已经选择了某些奖励函数R(.) 作为反馈,并运行了学习算法。然而它的表现似乎比人类飞行员要糟糕得多——它更加颠簸,而且似乎不那么安全。你如何判断错误是否由强化学习算法造成——它试图找到一个轨迹T,满足

——或者错误来自于你的奖励函数——它尝试衡量并且指定一种在颠簸程度和着陆精度之间权衡的理想结果。
为了应用优化验证测试,让Thuman 表示人类飞行员所选择的轨迹,并让Tout 代表算法所选择的轨迹。根据我们上面的描述,

是优于

的发展轨迹。因此,关键的测试点在于:

情况1:如果不等式成立,奖励函数R(.) 正确地使  优于 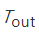 ,但这表明我们的强化学习算法找到的 . 仍不够好,花时间去改进算法是很值得的。
情况2:如果上面不等式不成立,而是

。这表明R(.) 的设计使得理应是更优策略的Thuman 得到了一个更糟的评分。你应当致力于改进R(.),以更好地获得与良好着陆情况相对应的权衡。
许多机器学习应用程序使用这种优化某个近似的 “模式” 来确定得分函数Scorex(.). 有时没有特定的输入x,形式简化为Score(.) 。在上面的例子中,得分函数即是奖励函数,Score(T)=R(T) ,而采用的优化算法是强化学习算法,目的是找到好的轨迹。
这和前面的例子有一个区别,那就是,与其比较 “最优” 输出,不如将其与人类水平的表现 进行比较。我们认为,即使 不是最优的,它也是相当不错的。一般而言,只要有一个比当前学习算法性能更好的输出y*(在这个例子中即是指 ),即使它不是 “最优” 的,优化验证测试也能够反映改进学习算法与改进得分函数之间哪一个更具前途。
原文链接
| 
 /2
/2 



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡



